Redis超时排查的示例分析
在我们前几天的工作中,我们突然接到了一个告警,提示我们的 Redis 已经崩溃了,而且还有许多人在讨论某个 Redis 的连接超时。当初以为是有大问题,谁知道它过了一会儿就恢复了。那个时候,我登上服务器,查看监控。第一时间看看 QPS:
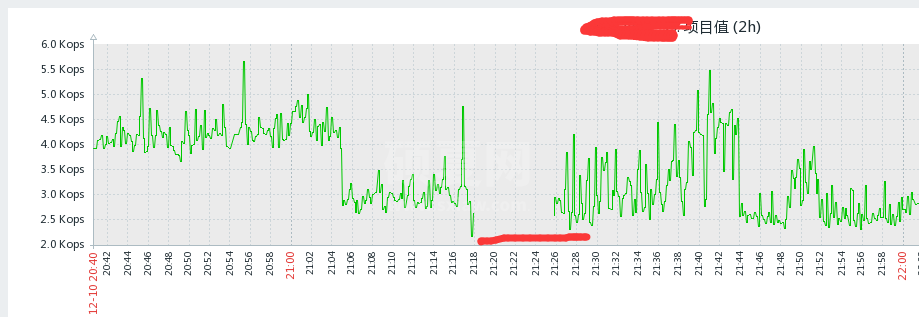
可以看到 QPS 并不高,但是中间有段时间没取到数据是怎么回事?那么继续看看 Redis 的 cpu 使用率:
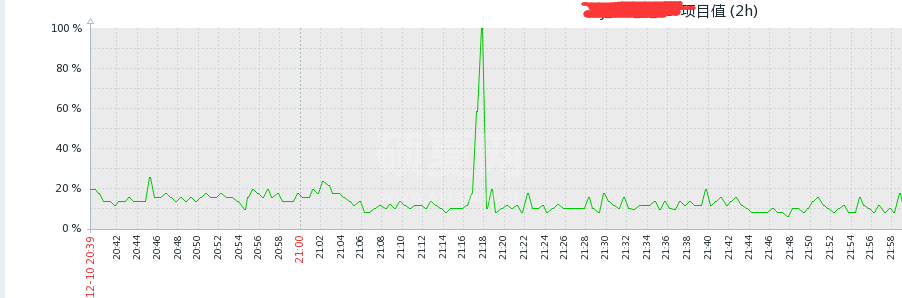
可以看到 cpu 已经饱和,这也就能解释为何断图了,因为 redis 是单线程,在使用 cpu 100% 以后,就无法处理其他的命令了,zabbix 也就无法执行 info 命令取 qps 了。那么已经知道是 cpu 使用饱和造成的问题,那么到底是什么原因呢?那么继续查看,cpu 使用高的这段时间有没有慢日志:
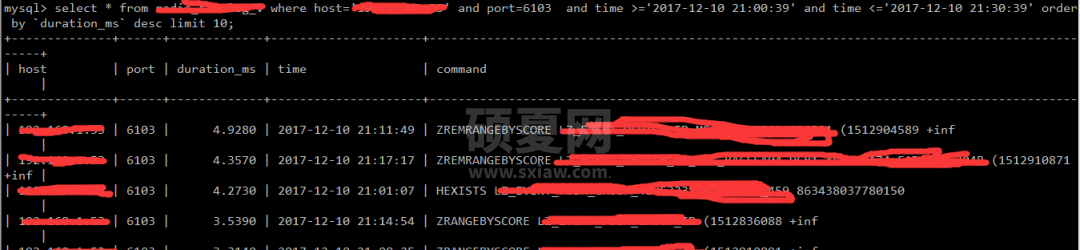
这似乎不是导致 CPU 占用率高的罪魁祸首,所以很难排查。这个示例是一个主节点和一个从属节点。那么我看看从库的 cpu 使用情况看看:
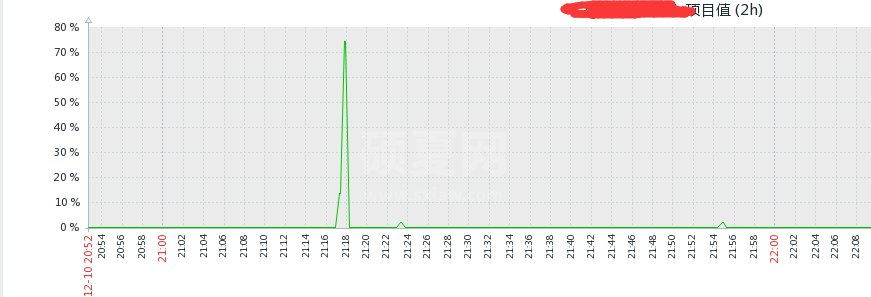
卧槽,怎么回事,从库没有使用的怎么 cpu 也用到了 74%?这不科学啊?管他的,看看从库有没有慢日志:

卧槽,怎么回事?从库没人使用啊。看看是否只读:
127.0.0.1:6103> CONFIG GET "slave-read-only" 1) "slave-read-only" 2) "yes" 127.0.0.1:6103>
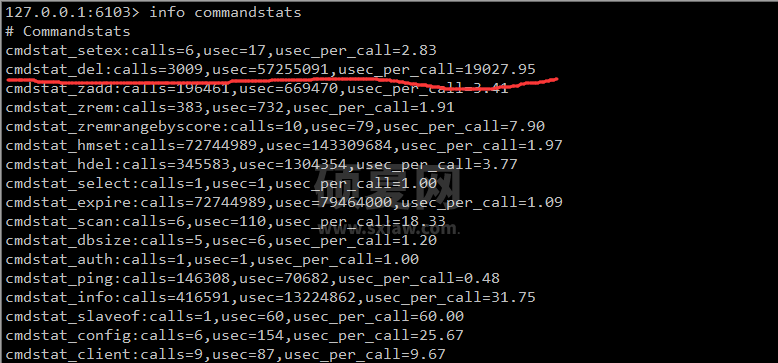
看来是只读的,这把我给整懵了。最后突然想到是主库在这个点有 big key 过期,而主库过期 key 操作慢是不会记录慢日志的,从库的 key 过期是由主库发起 DEL 指令删除的。这时从库就会记录慢日志,从上面慢日志可以看到这些 DEL 操作最大的 335ms,怪不得会有应用连接超时的。
再使用命令 info commandstats 看看:
以上就是Redis超时排查的示例分析的详细内容,更多请关注其它相关文章!