Redis主从技术的示例分析
Redis复制
在生产环境中,Redis通过持久化功能(RDB和AOF技术)保证了即使在服务器重启的情况下也不会损失(或少量损失)数据。但是由于数据是存储在一台服务器上的,如果这台服务器出现硬盘故障等问题(生产环境中多次遇到),也会导致数据丢失,为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务器上,这样即使有一台服务器出现故障,其他服务器依然可以以最快的速度提供服务。为此,Redis提供了复制(replication)功能,可以实现当一台数据库中的数据更新后,自动将更新的数据同步到其他数据库上。
数据库的复制概念可分为两类,主数据库(master)和从数据库(slave)。从数据库在主数据库发生写操作并导致数据变化时,会自动进行数据同步。而从数据库一般是只读的,并接受主数据库同步过来的数据。一个主数据库可以拥有多个从数据库。
Redis复制很简单易用,它通过配置允许slave Redis Servers或者Master Servers的复制品。接下来有几个关于redis复制的非常重要特性:
一个Master可以有多个Slaves。
Slaves能通过和其他slave的链接,除了可以接受同一个master下面slaves的链接以外,还可以接受同一个结构图中的其他slaves的链接。
redis复制是在master段是非阻塞的,这就意味着master在同一个或多个slave端执行同步的时候还可以接受查询。
复制在slave端也是非阻塞的,假设你在redis.conf中配置redis这个功能,当slave在执行的新的同步时,它仍可以用旧的数据信息来提供查询,否则,你可以配置当redis slaves去master失去联系是,slave会给发送一个客户端错误。
为了有多个slaves可以做只读查询,复制可以重复2次,甚至多次,具有可扩展性(例如:slaves对话与重复的排序操作,有多份数据冗余就相对简单了)。
通过复制可以避免master全量写硬盘的消耗:只要配置 master 的配置文件redis.conf来“避免保存”(注释掉所有”save”命令),然后连接一个用来持久化数据的slave即可。但需要确保masters不会自动重新启动(详见下文)
Redis复制配置
在Redis中使用复制功能非常容易,只需要在从数据库的配置文件中加入“slaveof 主数据复制 主数据库端口”即可。
主数据库无需进行任何配置。下面先来看看一个最简化的复制系统,我们在一台服务器上启动两个redis示例,监听在不同的端口,其中一个作为主数据库,另一个作为从数据库。
首先我们不加任何参数来启动一个redis实例作为主数据库:
$ redis-server --port 6379 &
该实例默认监听6379端口,然后加上slaveof参数启动另一个redis实例作为从数据库,并让其监听6380端口:
$ redis-server --port 6380 --slaveof 127.0.0.1 6379 &
查看一下实例的启动情况:
$ ps aux | grep redis root 2886 0.0 0.0 38652 4448 pts/0 Sl 16:57 0:00 redis-server *:6379 root 2889 0.0 0.0 36604 4368 pts/0 Sl 16:57 0:00 redis-server *:6380
此时在主数据库中的任何数据变化都会自动同步到从数据库中,我们打开redis-cli实例A并连接到数据库:
$ redis-cli -p 6379
再打开redis-cli实例B并连接到从数据库:
$ redis-cli -p 6380
这时我们使用INFO命令来分别在实例A和实例B中获取replication的相关信息。
127.0.0.1:6379> INfo replication# Replicationrole:master connected_slaves:1 slave0:ip=127.0.0.1,port=6380,state=online,offset=266,lag=1 master_repl_offset:266 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:2 repl_backlog_histlen:265
可以看到,实例A的角色(role)是master,即主数据库,同时已连接的从数据库(connectd_slaves)的个数为1个。
同样在实例B中获取响应的信息为:
127.0.0.1:6380> INfo replication# Replicationrole:slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:9 master_sync_in_progress:0 slave_repl_offset:378 slave_priority:100 slave_read_only:1 connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0
可以看到,实例B的role是slave,即从数据库,同时其主数据库的地址为127.0.0.1,端口为6379。
然后我们在实例A中使用SET命令设置一个键的值:
127.0.0.1:6379> set foo bar OK
此时在实例B中就可以获得该值了:
127.0.0.1:6380> get foo"bar"
证明两个Redis实例的复制功能已经可用了。默认情况,从数据库是只读的,如果直接修改从数据库的数据会出现错误,如下:
127.0.0.1:6380> set foo hey (error) READONLY You can't write against a read only slave.
但也可以通过设置从数据库的配置文件中的slave-read-only=no,以使从数据库可写,但是因为对从数据库的任何更改都不会同步给任何其他数据库,并且一旦主数据库中的更新了赌赢的数据就会覆盖从数据库中的改动,所以通常场景下不应该设置从数据库可写,以免导致易被忽略的潜在应用逻辑错误。
配置多台从数据库的方法也一样,在所有的从数据库的配置文件中都加上salveof参数指向同一个主数据库即可。除了通过配置文件或命令行参数设置slaveof参数外,还可以在运行时使用slaveof命令修改,下面我们再添加一个实例C(6381):
$ redis-server --port 6381 & $ redis-cli -p 6381 127.0.0.1:6381> slaveof 127.0.0.1 6379 127.0.0.1:6381> get foo"bar"
如果该数据库已经是其他主数据库的从数据库了,slaveof命令会停止和原来数据库的同步转而和新数据库同步,此外对于从数据库来说,还可以使用slaveof no one命令来使当前数据库停止接收其他数据库的同步并转换成为主数据库。如下测试,在从库实例C上写入数据时时不允许的,然后使用slaveof no one将此数据库转换为主数据库,然后再写入数据就没有问题了。一般用于但主节点挂掉的时候,立刻把从节点切换为主节点提供数据操作服务。
127.0.0.1:6381> set foo bar (error) READONLY You can't write against a read only slave. 127.0.0.1:6381> SLAVEOF no one 5493:M 07 Aug 17:23:06.792 # Connection with master lost. 5493:M 07 Aug 17:23:06.792 * Caching the disconnected master state. 5493:M 07 Aug 17:23:06.792 * Discarding previously cached master state. 5493:M 07 Aug 17:23:06.792 * MASTER MODE enabled (user request from 'id=2 addr=127.0.0.1:40825 fd=6 name= age=348 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=slaveof') 2886:M 07 Aug 17:23:06.792 # Connection with slave 127.0.0.1:6381 lost. OK 127.0.0.1:6381> set foo bar OK
复制常用参数
slaveof
将当前server做为slave,并为其指定master信息。
masterauth
以认证的方式连接到master,如果master中使用了”密码保护”,slave必须交付正确的授权密码,才能连接成功。”requirepas”配置项指定了当前server的密码。此配置项中值需要和master机器的”requirepas”保持一致。此参数配置在slave端。
slave-serve-stale-data yes
如果当前server是slave,那么当slave与master失去通讯时,是否继续为客户端提供服务,”yes”表示继续,”no”表示终止。如果在“yes”的情况下,从节点继续向客户端提供只读服务,数据有可能是过期的。在”no”情况下,任何向此server发送的数据请求服务(包括客户端和此server的slave)都将被告知”error”。
slave-read-only yes slave是否为”只读”,强烈建议为”yes”。 repl-ping-slave-period 10 slave向指定的master发送ping消息的时间间隔(秒),默认为10。 repl-timeout 60 slave与master通讯中,最大空闲时间,默认60秒,超时将导致连接关闭。 repl-disable-tcp-nodelay no slave与master的连接,是否禁用TCP nodelay选项。”yes”表示禁用,那么socket通讯中数据将会以packet方式发送(packet大小受到socket buffer限制),可以提高socket通讯的效率(tcp交互次数),但是小数据将会被buffer,不会被立即发送,对于接受者可能存在延迟。”no”表示开启tcp nodelay选项,任何数据都会被立即发送,及时性较好,但是效率较低。建议为”no”。 slave-priority 100 适用Sentinel模块(unstable,M-S集群管理和监控),需要额外的配置文件支持。slave的权重值,默认100。当master失效后,Sentinel将会从slave列表中找到权重值最低(>0)的slave,并提升为master。如果权重值为0,表示此slave为”观察者”,不参与master选举。
了解Redis的复制原理
了解Redis复制的原理有助于运维Redis过程中的规划节点和处理节点故障等问题。下面介绍Redis实现复制的工程。 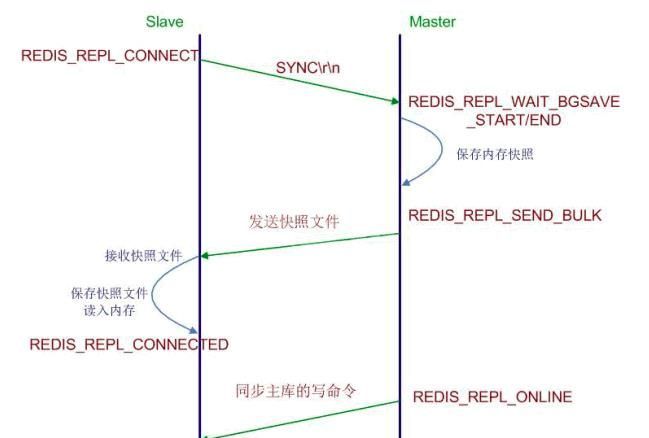
当一个从数据库启动后,会向主数据库发送SYNC命令,同时主数据库接收到SYNC命令后会开始在后台保存快照(即RDB持久化的过程),并将保存快照期间接收到的命令缓存起来,当快照完成后,Redis Master会将快照文件发送给从数据库,从数据库收到后,会载入快照文件。之后Redis Master会以Redis命令协议的格式,将写命令缓冲区中积累的所有内容都发送给从服务器。以上过程称为复制初始化,复制初始化结束后,主数据库每当收到写命令时就会将命令同步给从数据库,从而保证主从数据库数据一致。
你可以通过telnet命令来亲自验证这个同步过程:首先连上一个正在处理命令请求的Redis服务器,然后向它发送SYNC命令,过一阵子,你将会看到telnet会话接收到服务器发来的大段数据(.rdb文件),之后还会看到,所有的服务器执行过的写命令,都会重新发送到telnet会话来。
当主从数据库之间的连接断开重连后,Redis 2.6以及之前的版本会重新进行复制初始化(即主数据库重新保存快照并传送给从数据库),即使从数据库可以仅有几条命令没有收到,主数据库也必须要将数据库里的所有数据重新传送给从数据库。这使得主从数据库断线重连后的数据恢复过程效率很低下,在网络环境不好的时候这一问题尤其明显,Redis 2.8版本的一个重要改进就是断线重连能够支持有条件的增量数据传输,当从数据库重新连接上主数据库后,主数据库只需要将断线期间执行的命令传送给从数据库,从而大大提高Redis复制的实用性。
增量复制的实现,基于以下3点:
1)从数据库会存储主数据库的运行ID(run id),每个Redis运行实例均会拥有一个唯一的运行ID,每当实例重启后,就会自动生成一个新的运行ID。
2)在复制同步阶段,主数据库每将一个命令传送给从数据库时,都会同时把该命令存放到一个积压队列(backlog)中,并记录下当前积压队列中存放的命令的偏移量范围。
3)同时,从数据库接收到主数据库传来的命令时,会记录下该命令的偏移量。
这三点是实现增量复制的基础,当主从连接准备就绪后,从数据库会发送一条SYNC命令来告诉主数据库可以开始把所有数据同步过来了。而2.8版本之后,不再发送SYNC命令,取而代之的是发送PSYNC,格式为“PSYNC 主数据库的运行ID 断开前最新的命令偏移量”。收到PSYNC命令的主数据库将执行以下检查来确定是否可以进行增量复制。
1)首先主数据库会判断从数据库传送来的运行ID是否和自己的运行ID相同,这一步骤的意义在于确保从数据库之前确实是和自己同步的,以免从数据库拿到错误的数据(如主数据库在断连期间重启过,会造成数据的不一致性)。
2)然后判断从数据库最后同步成功的命令偏移量是否在积压队列中,如果在则可以执行增量复制,并将积压队列中相应的命令发送给从数据库。
如果此次重连不满足增量复制的条件,主数据会进行一次全部同步(即与Redis 2.6的过程相同),大部分情况下,增量复制的过程对开发者来说是完全透明的,开发者不需要关心增量复制的具体细节,2.8版本的主数据库也可以正常地和旧版本的从数据库同步(通过接收SYNC命令),同样2.8版本的从数据库也可以与旧版本的主数据库同步(通过发送SYNC命令),唯一需要开发者设置的就是积压队列的大小了。
积压队列在本质上是一个固定长度的循环队列,默认情况下积压队列的大小为1MB,可以通过配置文件的repl-backlog-size选项来调整。随着积压队列的增大,主从数据库断线的可容忍时间也随之延长,这是比较容易理解的。根据主从数据库之间的网络状态,设置一个合理的积压队列很重要。因为积压队列存储的内容是命令本身,如 SET FOO BAR,所以估算积压队列的大小只需要估计主从数据库断线的时间中主从数据库可能执行的命令的大小即可。与积压队列相关的另一个配置选项是repl-backlog-ttl,即当所有主从数据库与主数据断开连接后,经过多久时间可以释放积压队列的内存空间,默认时间是1小时。
从数据库持久化
另一个相对耗时的操作是持久化,为了提高性能,可以通过复制功能建立一个或多个从数据库,并在从数据库中启用持久化,同时在主数据库禁用持久化,当从数据库崩溃重启后主数据库会自动将时间同步过来,所以无需担心数据丢失。
然后当主数据库崩溃时,情况就稍显复杂了。手工通过从数据库数据恢复主数据库数据时,需要严格按照以下两步进行:
1)在从数据库中使用SLAVEOF NO ONE命令将从数据库提升为主数据库继续服务。
2)启动之前崩溃的主数据库,然后使用SLAVEOF命令将其设置成新的主数据库的从数据库,即可将数据同步回来。
注意,当开启复制且主数据库关闭持久化的时候,一定不要使用supervisor以及类似的进程管理工具令主数据库崩溃后自动重启。同样当主数据库所在的服务器因故关闭时,也要避免直接重新启动。这是因为当主数据库重新启动后,因为没开持久化功能,所以数据库中所有数据都被清空,这时从数据库依然会从主数据库中接收数据,使得所有从数据库也被清空,导致从数据库的持久化失去意义。
无论哪种情况,手工维护从数据库或主数据的重启以及数据恢复都相对麻烦,好在Redis提供了一种自动化方案哨兵来实现这一过程,避免了手工维护的麻烦和容易出错的问题。
无硬盘复制
上面介绍了Redis复制的工作原理时介绍了复制是基于RDB方式的持久化实现的,即主数据库端在后台保存了RDB快照,从数据库端则接收并载入快照文件,这样的实现有点是可以显著地简化逻辑,复用已有的代码,但是缺点也很明显。
1)当主数据库禁用RDB快照时(即删除了所有的配置文件中的save语句),如果执行了复制初始化操作,Redis依然会生成RDB快照,所以下次启动后主数据库会以该快照恢复数据。恢复的数据可能对应于任何时间点,因为无法确定复制发生的确切时间。
这个过程会对性能产生影响,因为复制初始化需要在硬盘中生成RDB快照文件,如果硬盘性能较慢。举例来说,当使用Redis做缓存系统时,因为不需要持久化,所以服务器的硬盘读写速度可能较差。但是当该缓存系统使用一主多从的集群架构时,每次和从数据库同步,Redis都会执行一次快照,同时对硬盘进行读写,导致性能下降。
因此从2.8.18版本开始,Redis引入了无硬盘复制选项,开启该选项时,Redis在与从数据库进行复制初始化时将不会将快照内容存储到硬盘上,而是直接通过网络发送给从数据库,避免了硬盘的性能瓶颈。可以在配置文件中使用如下配置来开启该功能:
repl-diskless-sync yes
PS:当需要把Slave转换为Master时可以使用”SLAVEOF ON ONE”指令。
以上就是Redis主从技术的示例分析的详细内容,更多请关注其它相关文章!