怎么用Mysql存储过程造百万级数据
1.准备工作
(1)由于是使用存储过程,mysql从5.0版开始支持存储过程,那么需要mysql的版本在5.0或者以上。如何查看mysql的版本,使用下面sql语句查看:

(2)创建两张表,表结构一致,但使用的存储引擎不一样,如下所示,普通表使用mysql5.5版本后默认的INNODB存储引擎,内存表使用MEMORY存储引擎。
由于MEMORY存储不常用这里简单说一下其特点:MEMORY引擎表结构创建在磁盘上,数据全部放在内存中,访问速度较快,但是当MySQL重启后或者一旦系统奔溃的话,数据都会消失,结构还存在。
# 创建普通表
CREATE TABLE `user_info` (
`id` INT ( 11 ) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`name` VARCHAR ( 30 ) NOT NULL COMMENT '用户名',
`phone` VARCHAR ( 11 ) NOT NULL COMMENT '手机号',
`status` TINYINT ( 1 ) NULL DEFAULT NULL COMMENT '用户状态:停用0,启动1',
`create_time` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY ( `id` ) USING BTREE
) ENGINE = INNODB AUTO_INCREMENT = 10001 CHARACTER
SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '用户信息表';
# 创建内存表
CREATE TABLE `memory_user_info` (
`id` INT ( 11 ) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`name` VARCHAR ( 30 ) NOT NULL COMMENT '用户名',
`phone` VARCHAR ( 11 ) NOT NULL COMMENT '手机号',
`status` TINYINT ( 1 ) NULL DEFAULT NULL COMMENT '用户状态:停用0,启动1',
`create_time` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY ( `id` ) USING BTREE
) ENGINE = MEMORY AUTO_INCREMENT = 10001 CHARACTER
SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '用户信息内存表';2.主要实现步骤
(1)创建自动生成数据的函数,插入时使用;
(2)创建插入内存表数据存储过程,调用已创建好的数据生成函数;
(3)创建内存表数据插入普通表存储过程;
(4)调用存储过程。
(5)数据查看验证
3.创建自动生成数据的函数
(1)生成n个随机数字
DELIMITER //
DROP FUNCTION
IF
EXISTS randomNum // CREATE FUNCTION randomNum (
n INT,
chars_str VARCHAR ( 10 )) RETURNS VARCHAR ( 255 ) BEGIN
DECLARE
return_str VARCHAR ( 255 ) DEFAULT '';
DECLARE
i INT DEFAULT 0;
WHILE
i < n DO
SET return_str = concat(
return_str,
substring( chars_str, FLOOR( 1 + RAND()* 10 ), 1 ));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER;函数运行截图:

脚本所用到的mysql函数及其功能如下:
a.concat():将多个字符串连接成一个字符串。
b.Floor():向下取整。
c.substring(string, position, length)
第一个参数:string指的是需要截取的原字符串。
第二个参数:position指的是从哪个位置开始截取子字符串,这里字符的位置编码序号是从1开始,若position为负数则从右往左开始数位置。
第三个参数:length指的是需要截取的字符串长度,如果不写,则默认截取从position开始到最后一位的所有字符。
d.RAND():只能生成0到1之间的随机小数。
(2)创建随机生成手机号函数
DELIMITER //
DROP FUNCTION
IF
EXISTS getPhone // CREATE FUNCTION getPhone () RETURNS VARCHAR ( 11 ) BEGIN
DECLARE
head CHAR ( 3 );
DECLARE
phone VARCHAR ( 11 );
DECLARE
bodys VARCHAR ( 65 ) DEFAULT "130 131 132 133 134 135 136 137 138 139 186 187 189 151 157";
DECLARE
STARTS INT;
SET STARTS = 1+floor ( rand()* 15 )* 4;
SET head = trim(
substring( bodys, STARTS, 3 ));
SET phone = trim(
concat(
head,
randomNum ( 8, '0123456789' )));
RETURN phone;
END //
DELIMITER;函数运行截图:

(3)创建随机生成用户名函数
DELIMITER //
DROP FUNCTION
IF
EXISTS randName // CREATE FUNCTION randName ( n INT ) RETURNS VARCHAR ( 255 ) CHARSET utf8mb4 DETERMINISTIC BEGIN
DECLARE
chars_str VARCHAR ( 100 ) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
DECLARE
return_str VARCHAR ( 30 ) DEFAULT '';
DECLARE
i INT DEFAULT 0;
WHILE
i < n DO
SET return_str = concat(
return_str,
substring( chars_str, FLOOR( 1 + RAND() * 62 ), 1 ));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER;函数运行截图:
(4)随机生成用户状态函数
DELIMITER //
DROP FUNCTION
IF
EXISTS randStatus // CREATE FUNCTION randStatus ( ) RETURNS TINYINT ( 1 ) BEGIN
DECLARE
user_status INT ( 1 ) DEFAULT 0;
SET user_status =
IF
( FLOOR( RAND() * 10 ) <= 4, 1, 0 );
RETURN user_status;
END //
DELIMITER;函数运行截图:

(5)查看数据库中所有自定义函数信息

4.创建存储过程
(1)创建插入内存表数据存储过程
DELIMITER //
DROP FUNCTION
IF
EXISTS randStatus // CREATE FUNCTION randStatus ( ) RETURNS TINYINT ( 1 ) BEGIN
DECLARE
user_status INT ( 1 ) DEFAULT 0;
SET user_status =
IF
( FLOOR( RAND() * 10 ) <= 4, 1, 0 );
RETURN user_status;
END //
DELIMITER;入参n是多少就表示往内存表memory_user_info插入多少条数据
存储过程运行截图:

(2)创建内存表数据插入普通表存储过程
DELIMITER //
DROP PROCEDURE
IF
EXISTS add_user_info // CREATE PROCEDURE `add_user_info` ( IN n INT, IN count INT ) BEGIN
DECLARE
i INT DEFAULT 1;
WHILE
( i <= n ) DO
CALL add_memory_user_info ( count );
INSERT INTO user_info SELECT
*
FROM
memory_user_info;
DELETE
FROM
memory_user_info;
SET i = i + 1;
END WHILE;
END //
DELIMITER;这是最主要的存储过程,也是入口,利用对内存表的循环插入和删除来实现批量生成数据,不需要更改mysql默认的max_heap_table_size值(默认值是16M),max_heap_table_size 的作用是配置用户创建内存临时表的大小,配置的值越大,能存进内存表的数据就越多。
存储过程运行截图:

(3)查看存储过程的状态
-- 查看数据库所有的存储过程 SHOW PROCEDURE STATUS; -- 模糊查询存储过程 SHOW PROCEDURE STATUS LIKE 'add%';
模糊查询结果:

5.调用存储过程
mysql称存储过程的执行为调用,因此mysql执行存储过程的语句为CALL。CALL接受存储过程的名字以及需要传递给它的任意参数。
通过调用add_user_info存储过程,不断循环插入内存表memory_user_info,再从内存表获取数据插入普通表user_info,然后删除内存表数据,以此循环直至循环结束。循环100次,每次生成10000条数据,共生成一百万条数据。
CALL add_user_info(100,10000);
6.数据查看验证
在普通表数据达到6万条时,已经耗时大概在23分钟左右,以这个时间推算,100万数据生成预计需要6小时左右。耗时的点主要是在四个随机生成字段数据的函数上。如果字段数据不要求随机,那么将会快很多。

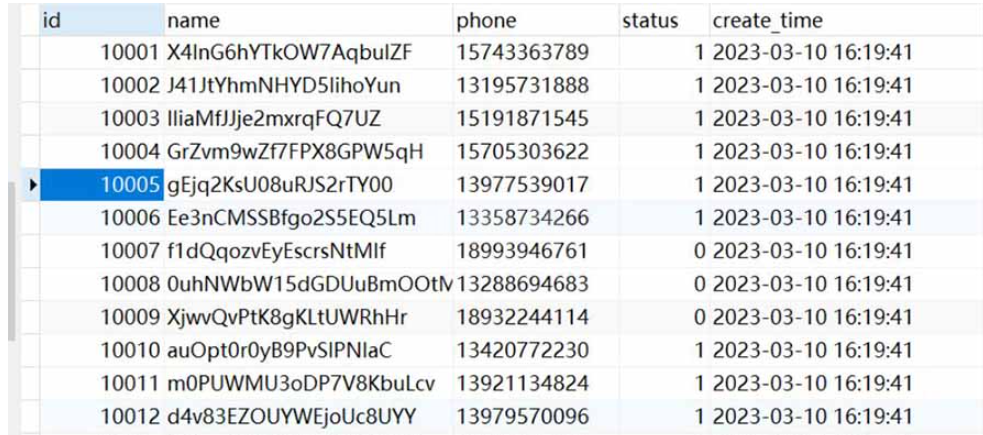
数据记录如下效果:
以上就是怎么用Mysql存储过程造百万级数据的详细内容,更多请关注其它相关文章!