业务指数级增长,可用性建设也可以如此稳当?
一、问题与挑战
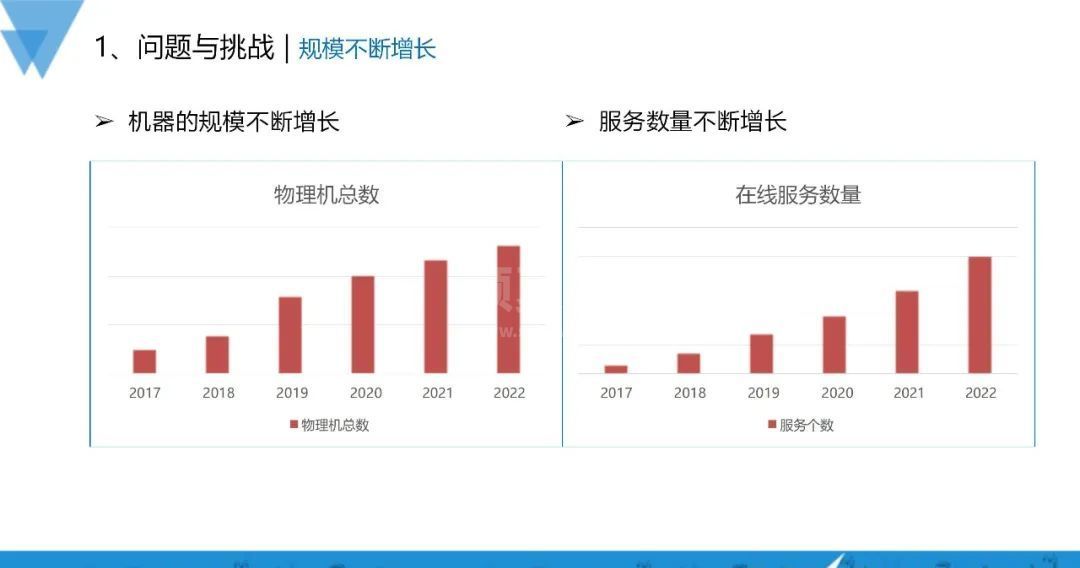
自2017年起,vivo的机器规模和服务数量都有显著增长,这可以从图表中看出。机器规模大约增长了五倍左右,服务数量也基本上增长了十几倍,其时间跨度为从2017年至2022年。
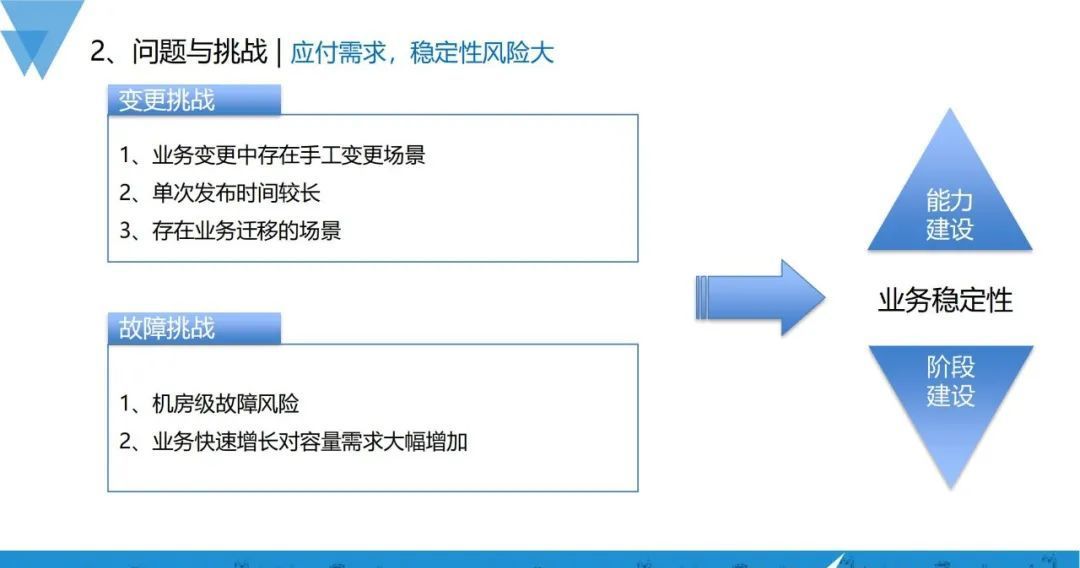
在规模增长的情况下,挑战和复杂度肯定随之上升,在vivo比较典型的挑战主要分为变更挑战和故障挑战。
1、变更挑战
变更中还是存在着或多或少的手工变更场景;
我们的单次的发布时间是比较长的;
存在很多的业务大量迁移的场景;
谷歌SRE有这样一个概念:70%的故障是由变更引起的。在vivo也存在这种情况,变更对线上稳定性会有很大的影响。
2、故障挑战
- 机房级故障风险(大小公司都会遇到,光纤挖断或机房内部故障等);
- 业务快速增长对容量需求大幅增加。
在此挑战下,我们分为了可用性能力和可用性阶段两个维度去建设,以此保障业务的稳定性。
二、可用性能力建设
1、基于故障的全生命周期开展

我们的可用性能力建设是基于全周期故障管理开展的,涵盖故障发生、发现、响应、恢复、复盘及预防措施。从故障发生到恢复的时间,称为MTTR;从故障的恢复到发生,从稳定到不稳定,称为MTTF;故障发生的间隔时间,称为MTBF,总计3个指标。
故障管理无非就是这4点:
- 如何预防故障的发生?
- 如何尽快发现故障?
- 如何快速进行故障治愈?
- 故障恢复后,如何复盘跟进?
主要从业务可用性方面考虑,需要关注故障的发生频率以及对业务的影响时间。所以,减少故障发生频次、快速定位故障发生、缩短故障持续时间、实现故障快速治愈,就是我们整个高可用能力建设的大体思路。下面从我们已落地的措施跟大家介绍:
2、故障发生分析
首先,要实现故障预防,首先要了解故障为什么发生,可以从服务视角和全链路视角来看。
1)服务视角
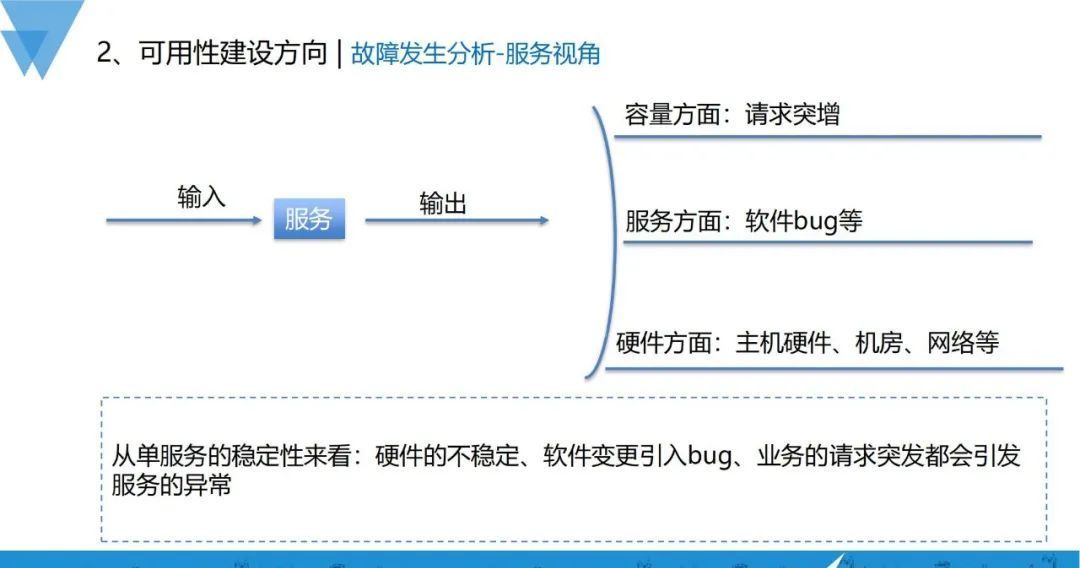
一个服务,无非就是有请求的输入,正常来说有相应的输出就可以。在实际情况下,有很多方面会影响服务的正确响应。在一些经典场景中,已经总结出了影响因素
- 容量方面:业务请求倍数级增长,会导致单个服务的输出异常;
- 服务方面:软件本身有bug在运行,结果服务运行crush了;
- 硬件方面:主机硬件、机房、网络导致的异常。
2)全链路视角

- 容量层:请求突增,全链路的容量不足,导致服务出现异常;
- 服务层:服务和服务之间需要协同配置,配置设置不对也会导致全链路异常;
- 上下游依赖:一些关键服务的异常,会导致整个链路的异常。
从全链路的稳定性来看:上下游的依赖、容量不足和服务配置异常等,都是影响稳定性的重要因素。
3、故障预防建设
从服务和全链路两个角度分析故障因素之后,故障预防建设就有了相应的思路:
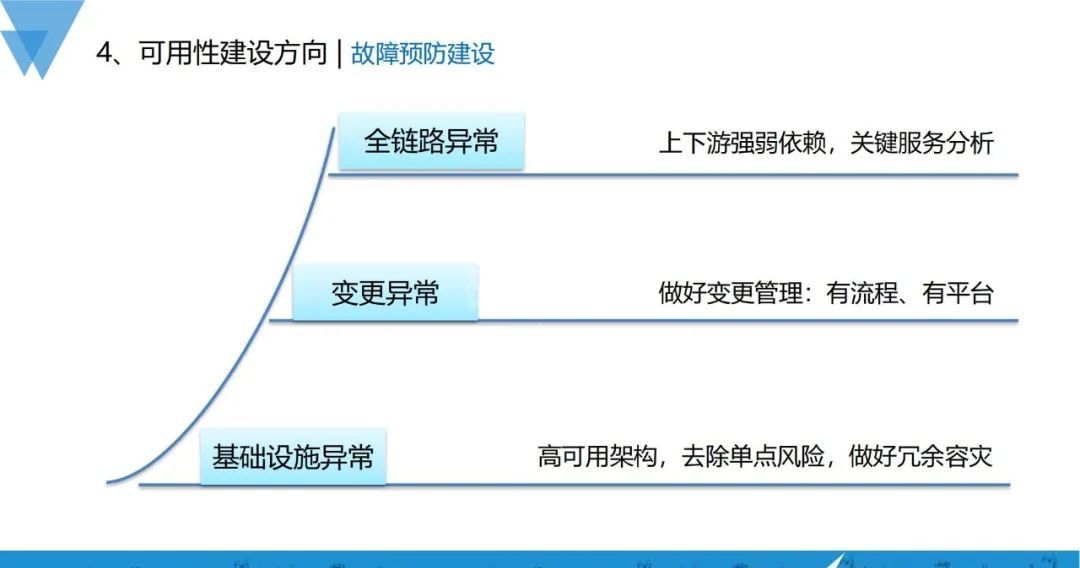
- 全链路异常:要做好上下游强弱依赖分析,并对关键的服务器做专项保障,以此保障全链路的稳定性;
- 变更异常:建立变更流程规范、变更管理平台;
- 基础设施异常:依赖高可用架构,去除单点风险,做好冗余容灾。
4、故障预防
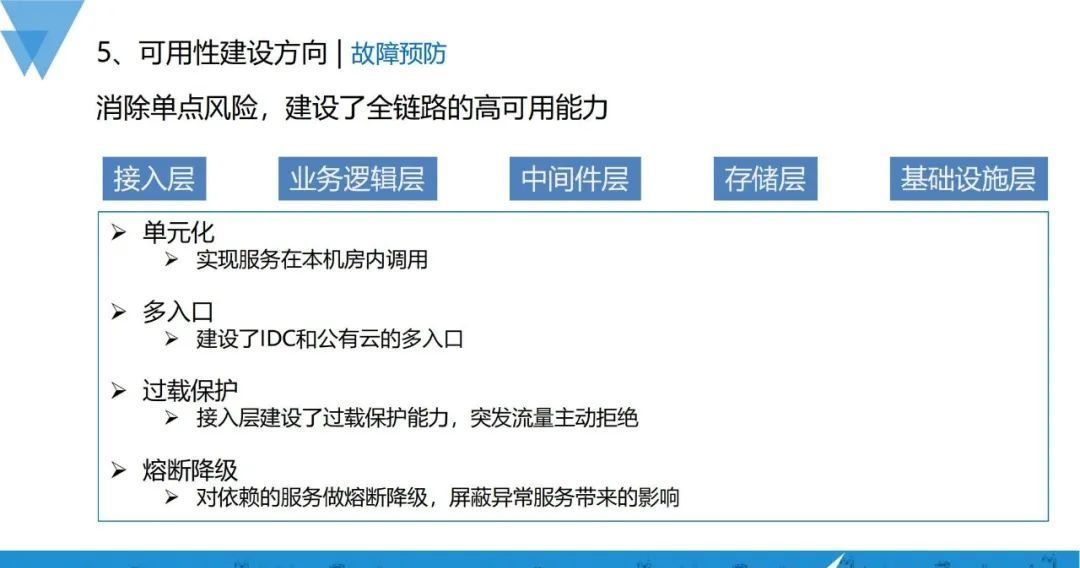
前面讲了整体的分析和建设思路,实际上vivo是怎么做的呢?
我们基于全链路做了建设保障,整个链路从接入层、业务逻辑层、中间件层、存储层、基础设施层进行了建设:
1)单元化:减少跨机房之间的服务调用,避免单机房的故障影响到所有机房服务;
2)多入口:之前很多业务只有单个接入层入口,建设IDC和公有云的多入口能力之后,单个入口异常对服务整体接入的影响就会变小;
3)过载保护:当业务突增容量的时候,接入层服务根据设置能够主动拒绝部分突发请求,防止过高的请求流量把后面的服务打垮;
4)熔断降级:对依赖服务做好垄断降级,可以屏蔽异常服务带来的影响,避免雪崩效应。
5、故障发现
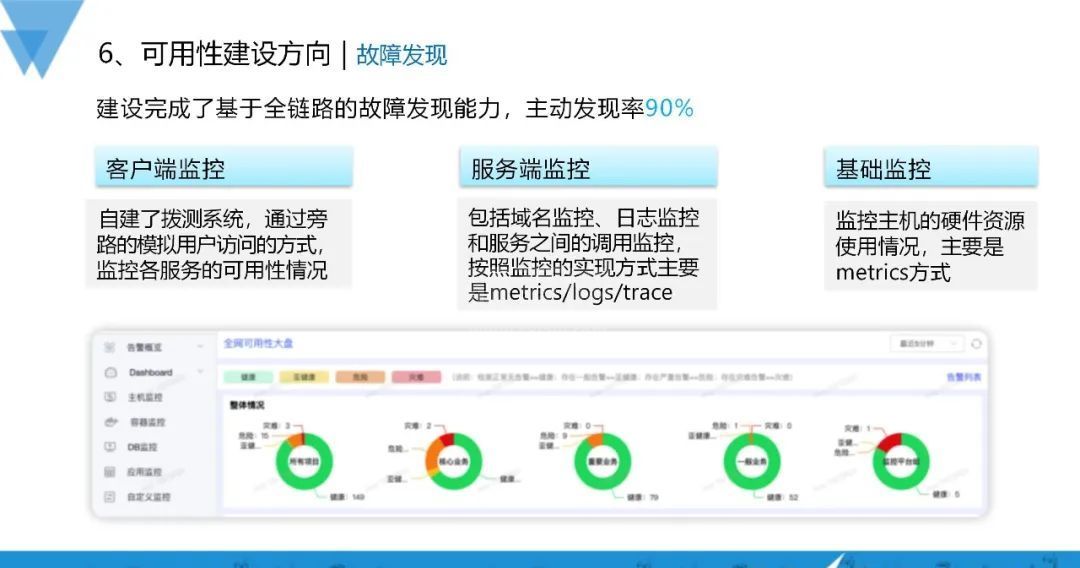
我们建设了基于全链路的故障发现能力,目到故障主动发现率能达到90%,这当中包括客户端监控、服务端监控和基础监控:
1)客户端监控:自建拨测系统,通过旁路的模拟用户访问方式,监控各服务的可用性情况;
2)服务端监控:包括域名监控、日志监控和服务之间的调用监控,按照监控的实现方式主要是metrics/logs/trace;
3)基础监控:监控主机的硬件资源使用情况,主要是metrics方式。
6、故障处理
主要包括故障分析和故障处理。

- 故障分析:和监控系统联动,支持基础服务故障分析、域名可用性分析等;
- 故障处理:故障预案建设,包括预案的制定、演练等。
7、故障复盘
故障复盘在整个高可用建设周期里面是非常重要的一环。

我们通过基于业务的SLA分级,有的放矢地去保证业务的稳定性,并做好业务的每一个故障记录,改进和验证能力建设:
1)业务分级:运维资源非常有限,保证保障所有业务有相同的SLA,因此分级保障是非常有必要的,我们基于业务的口碑、营收,分为核心、重要、一般、其它四个业务级别,以此指导投入到各业务的运维人力和保障力度;
2)故障记录:提高复盘效率,同时跟踪线上业务故障做后续分析,以此指导业务进行优化;
3)故障改进:基于混沌工程做后向验证,判断改进措施是否有落地生效。
这是我们在故障复盘上的实践,我们也将这些能力和实践落地到了平台,通过平台去管理故障复盘工作。
8、容量管理
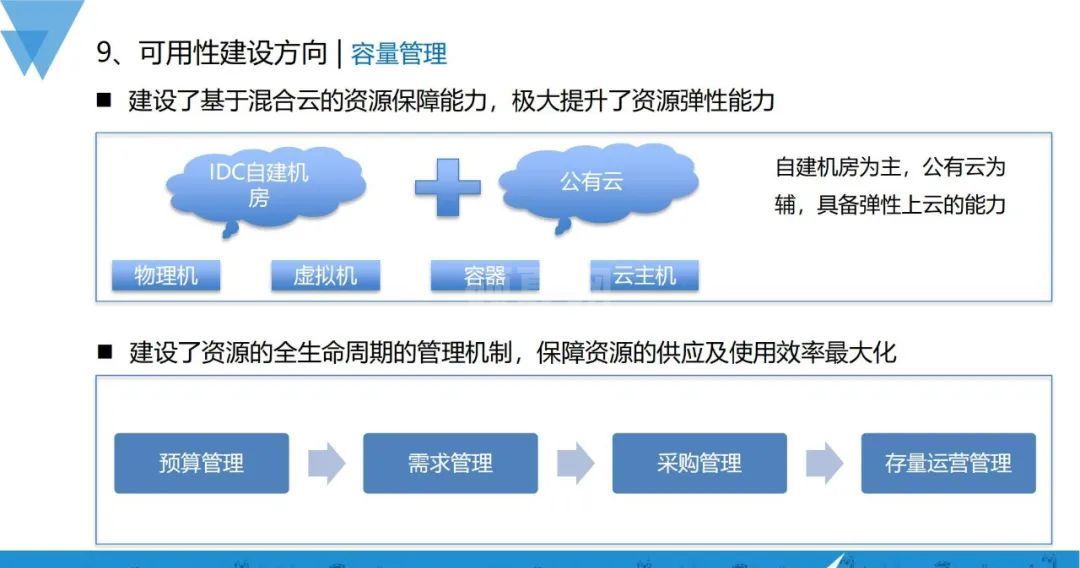
线上故障很多都是容量问题导致的,容量资源到位后,可用性也能得到一定的保障,在这方面,我们主要提升了两方面的能力:资源弹性伸缩能力、资源交付运营管理能力。
- 资源弹性伸缩能力:建设基于混合云的资源保障能力,极大提升资源弹性能力;
- 资源交付运营管理能力:建设资源的全生命周期的管理机制,保证资源的供应跟使用效率最大化,实现了包括预算管理、需求管理、采购管理、存量运营管理。
三、可用性阶段建设
在可用性能力建设之后,我们分成三个阶段去建设可用性:标准性阶段、流程性阶段、平台化阶段。
1、标准化阶段

为什么要建设标准化?
标准化能够极大地减轻业务的运维复杂度,从而降低运维成本。我们在硬件和软件层面,都做了很多标准化工作。
- 硬件层面:机房标准化、网络标准化(公网、主动上网、内网专线);
- 软件层面:OS标准化、主机环境标准化、服务目录标准化、Agent标准化、接入nginx集群标准化、服务能力标准化(中间件服务)。
2、流程化与规范化建设
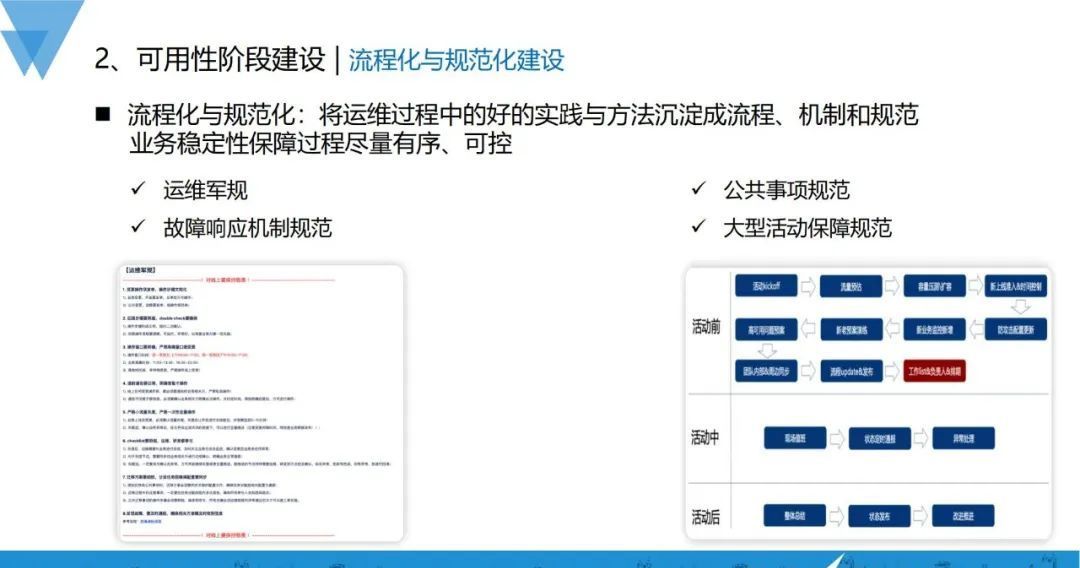
首先,我们会将运维过程中做得比较好的实践和方法沉淀成流程机制和规范,让业务稳定性保障有序可控,包括运维军规、故障响应机制、公共事项规范、大型活动保障规范等。
例如大型活动的保障规范,在规范没有建立起来之间,如有大型运营活动或春节红包派送活动的时候,线上很容易出故障,自从2018年把大型活动保障规范建立起来之后,春节等重保都能保障平稳运行。
3、平台与系统建设
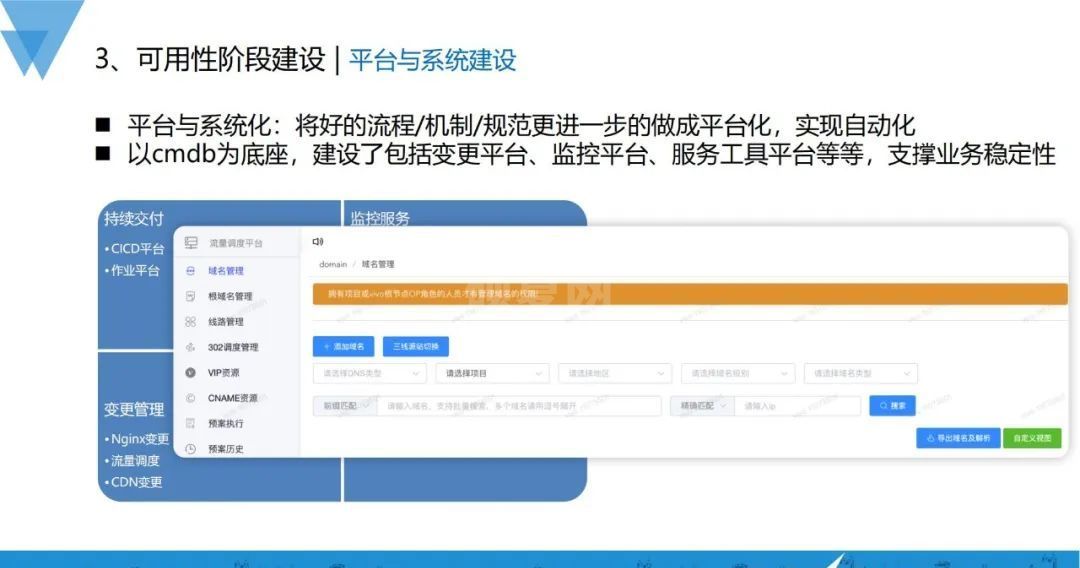
在平台与系统建设上,以CMDB为底座,把往常较好的流程机制更进一步做成平台,如变更平台、监控平台、服务工具平台等,以此支撑业务稳定性。
四、可用性结果与展望
到2022年,整体业务稳定性运维实现有序高效,业务可用性从之前的3个9提升到现在4个9,达标的业务个数也从之前的8个到现在的24个。
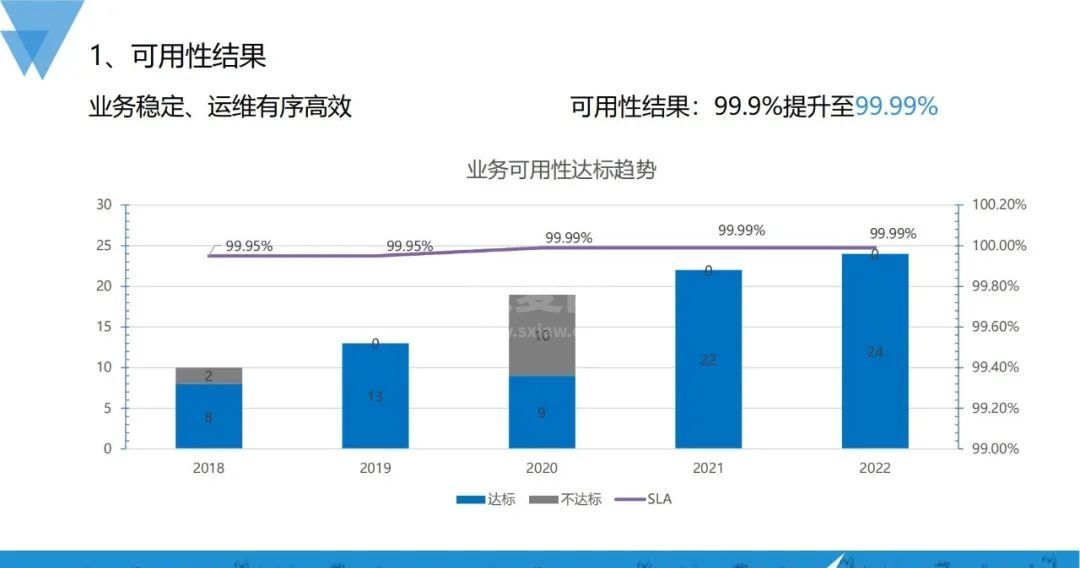
达到这个可用性结果,主要就是通过可用性能力建设和可用性阶段建设:
- 可用性能力建设:故障预防、故障发现、故障治愈、故障复盘
- 可用性阶段建设:标准化、流程/规范化、平台/自动化

未来,我们会重点关注异地多活、容器/云原生的可用性保障。
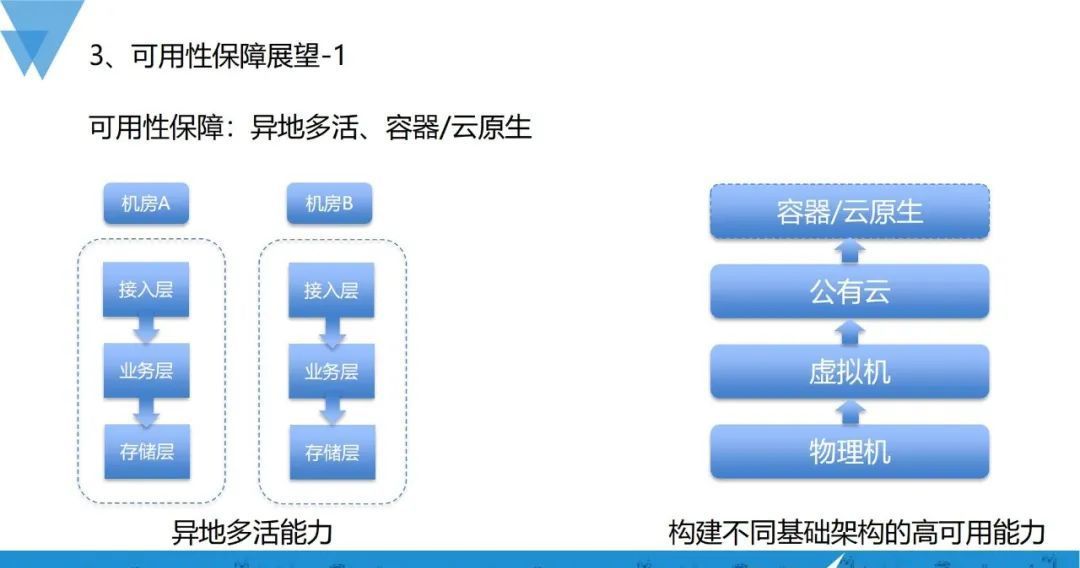
以容器、云原生方面的可用性保障为例,我们之前更多的是纯物理机,后面增加了虚拟机,再到后来补充了公有云,进一步降低了对底层基础设施的直接依赖,同时我们也在做容器、云原生,将资源单元化、灵活调度,降低对物理硬件资源的直接依赖,因此我们要构建不同基础架构的高可用能力。
可用性建设还能做些什么?

我个人认为,我们不单单只是考虑可用性,业务的质量和运营成本都是需要我们考虑的,业务的运维保障后续要进入到精细化运营保障阶段。
Q&A
Q1:在可用性建设落地的过程中,遇到的最大难点是什么?
A1:第一点是底层技术能力的建设规范,这些规范如果不准守会导致业务可用性结果存在很大的不确定性,所以要对团队制定一定的规范,同时也要有一定的守底机制;
第二点是上层认可,每个业务在不同的阶段诉求是不一样的,稳定性做得不好,会影响业务、口碑和营收,获得上层的认可后,可用性建设也更容易推动。
Q2:请问贵司在CMDB落地过程中,除了关联开发负责人、主机等信息,在实际过程中还关联过哪些信息?比如是否关联中间件的信息?
A2:我们很多系统当前都是以CMDB为底座的,不仅仅是运维系统,很多系统都是基于CMDB去搭建的,中间件服务也会和CMDB做关联建设,比如微服务里面的dubbo,也是基于CMDB去做服务发现和治理。
讲师介绍
周甲黎现在是vivo的运维总监,负责vivo互联网业务的运营和维护工作。这位曾经在百度和腾讯工作过的人,拥有客户端、国际化和大数据算法等离线业务运维方面的经验。加入vivo后,我主导了业务高可用性的建设,将业务的可用性提升至99.99%的水平。
以上就是业务指数级增长,可用性建设也可以如此稳当?的详细内容,更多请关注www.sxiaw.com其它相关文章!