Python常见的归一化方法有什么作用
数据归一化是深度学习数据预处理中非常关键的步骤,可以起到统一量纲,防止小数据被吞噬的作用。
一:归一化的概念
归一化就是把所有数据都转化成[0,1]或者[-1,1]之间的数,其目的是为了取消各维数据之间的数量级差别,避免因为输入输出数据数量级差别大而造成网络预测误差过大。
二:归一化的作用
为了后面数据处理的方便,归一化可以避免一些不必要的数值问题。
为了程序运行时收敛速度更快
统一量纲。样本数据的评价标准不一样,需要对其量纲化,统一评价标准,这算是应用层面的需求。
避免神经元饱和。就是说当神经元的激活在接近0或者1时,在这些区域,梯度几乎为0,这样在反向传播过程中,局部梯度就会接近于0,这样非常不利于网络的训练。
保证输出数据中数值小的不被吞食。
三:归一化的类型
1:线性归一化
线性归一化也被称为最小-最大规范化;离散标准化,是对原始数据的线性变换,将数据值映射到[0,1]之间。用公式表示为:

差标准化保留了原来数据中存在的关系,是消除量纲和数据取值范围影响的最简单的方法。代码实现如下:
def MaxMinNormalization(x,Max,Min):
x = (x - Min) / (Max - Min);
return x适用范围:比较适用在数值比较集中的情况
缺点:
如果max和min不稳定,很容易使得归一化的结果不稳定,使得后续使用效果也不稳定。如果遇到超过目前属性[min,max]取值范围的时候,会引起系统报错。需要重新确定min和max。
如果数值集中的某个数值很大,则规范化后各值接近于0,并且将会相差不大。(如 1,1.2,1.3,1.4,1.5,1.6,10)这组数据。
2:零-均值归一化(Z-score标准化)
Z-score标准化也被称为标准差标准化,经过处理的数据的均值为0,标准差为1。其转化公式为:
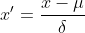
其中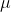 为原始数据的均值,
为原始数据的均值,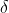 为原始数据的标准差,是当前用的最多的标准化公式
为原始数据的标准差,是当前用的最多的标准化公式
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,这里的关键在于复合标准正态分布
代码实现如下:
def Z_ScoreNormalization(x,mu,sigma):
x = (x - mu) / sigma;
return x3:小数定标规范化
这种方法通过移动属性值的小数数位,将属性值映射到[-1,1]之间,移动的小数位数取决于属性值绝对值的最大值。转换公式为:
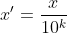
4:非线性归一化
这个方法包括log,指数,正切
适用范围:经常用在数据分析比较大的场景,有些数值很大,有些很小,将原始值进行映射。
四:批归一化(BatchNormalization)
1:引入
在以往的神经网络训练时,仅仅只对输入层数据进行归一化处理,却没有在中间层进行归一化处理。虽然我们对输入数据进行了归一化处理,但是输入数据经过了这样的矩阵乘法之后,其数据分布很可能发生很大改变,并且随着网络的层数不断加深。数据分布的变化将越来越大。因此这种在神经网络中间层进行的归一化处理,使得训练效果更好的方法就被称为批归一化(BN)
2:BN算法的优点
减少了人为选择参数
减少了对学习率的要求,我们可以使用初始状态下很大的学习率或者当使用较小的学习率时,算法也能够快速训练收敛。
破换了原来的数据分布,一定程度上缓解了过拟合(防止每批训练中某一个样本经常被挑选到)
减少梯度消失,加快收敛速度,提高训练精度。
3:批归一化(BN)算法流程
输入:上一层输出结果X={x1,x2,.....xm},学习参数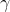 ,
,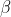
算法流程:
1)计算上一层输出数据的均值:
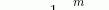
其中,m是此次训练样本batch的大小。
2)计算上一层输出数据的标准差:
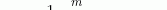
3)归一化处理得到
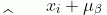
公式中的 是为了避免分母为0而加进去接近于0的很小的值。
是为了避免分母为0而加进去接近于0的很小的值。
4)重构,对经过上面归一化处理得到的数据进行重构,得到:
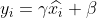
其中,为可学习的参数。
以上就是Python常见的归一化方法有什么作用的详细内容,更多请关注其它相关文章!