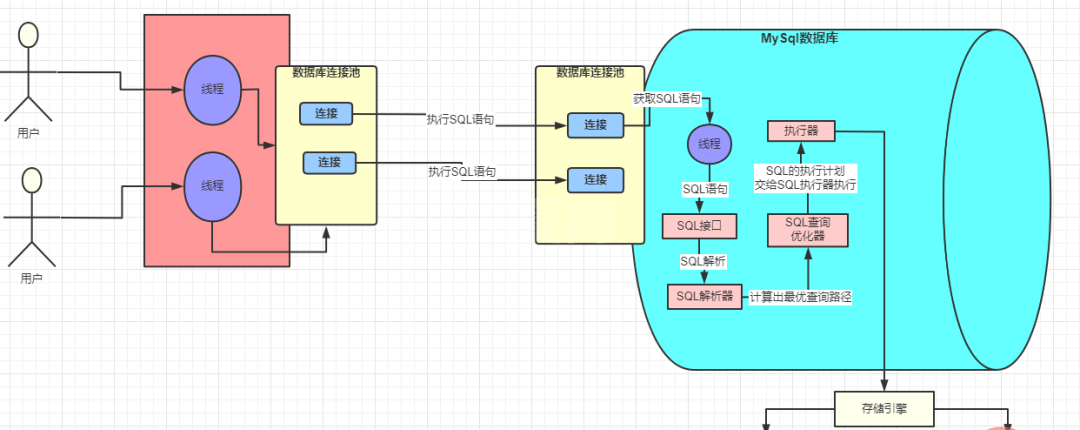
执行一句SQL的情况

推荐(免费):SQL
零、数据库驱动
- MySQL 驱动在底层帮我们做了对数据库的连接,只有建立了连接了,才能够有后面的交互。
一、数据库连接池
- 数据库连接池有 Druid、C3P0、DBCP
- 采用连接池大大节省了不断创建与销毁线程的开销,这就是有名的「池化」思想,不管是线程池还是 HTTP 连接池,都能看到它的身影
二、SQL 接口
三、查询解析器
四、MySQL 查询优化器
- MySQL 会依据成本最小原则来选择使用对应的索引
- 成本 = IO 成本 + CPU 成本
- IO成本 : 即从磁盘把数据加载到内存的成本,默认情况下,读取数据页的 IO 成本是 1,MySQL 是以页的形式读取数据的,即当用到某个数据时,并不会只读取这个数据,而会把这个数据相邻的数据也一起读到内存中,这就是有名的程序局部性原理,所以 MySQL 每次会读取一整页,一页的成本就是 1。所以 IO 的成本主要和页的大小有关
- CPU 成本:将数据读入内存后,还要检测数据是否满足条件和排序等 CPU 操作的成本,显然它与行数有关,默认情况下,检测记录的成本是 0.2。
- MySQL 优化器 会计算 「IO 成本 + CPU」 成本最小的那个索引来执行
五、存储引擎
- 查询优化器会调用存储引擎的接口,去执行 SQL,也就是说真正执行 SQL 的动作是在存储引擎中完成的。
- 数据是被存放在内存或者是磁盘中的
- 每次在执行 SQL 的时候都会将其数据加载到内存中,这块内存就是 InnoDB 中一个非常重要的组件:缓冲池 Buffer Pool
六、执行器
- 执行器最终最根据一系列的执行计划去调用存储引擎的接口去完成 SQL 的执行
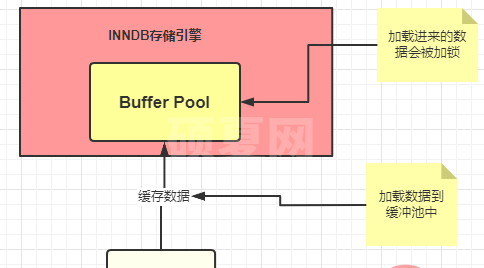
七、Buffer Pool
- Buffer Pool (缓冲池)是 InnoDB 存储引擎中非常重要的内存结构,起到一个缓存的作用
- Buffer Pool 就是我们第一次在查询的时候会将查询的结果存到 Buffer Pool 中,这样后面再有请求的时候就会先从缓冲池中去查询,如果没有再去磁盘中查找,然后在放到 Buffer Pool 中
- Buffer Pool中被使用的数据回被加锁。
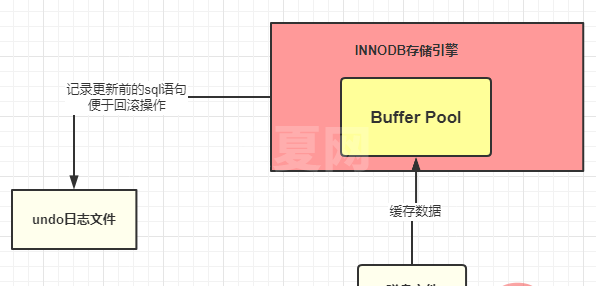
八、三个日志文件
1、undo 日志文件:记录数据被修改前的样子
- 作用:利用undo 日志文件完成事务回滚
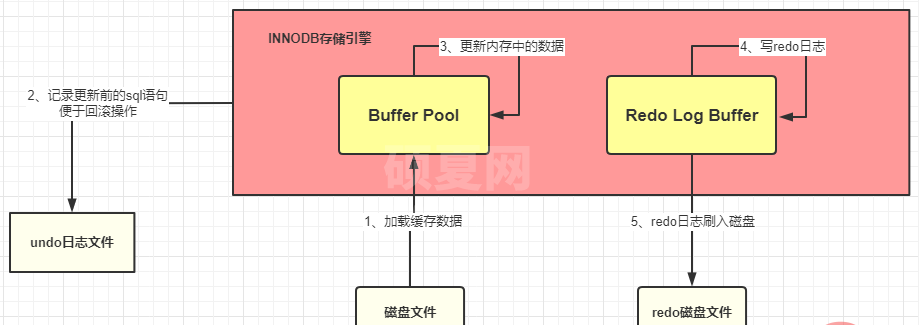
2、redo 日志文件:记录数据被修改后的样子
- redo 记录的是数据修改之后的值,不管事务是否提交都会记录下来
- MySQL 为了提高效率,所以将这些操作都先放在内存中去完成,更新后的数据会记录在 redo log buffer 中,然后会在某个时机将其持久化到磁盘中。
3、bin log 日志文件: 记录整个操作过程
| 性质 | redo Log | bin Log |
|---|---|---|
| 文件大小 | redo log 的大小是固定的(配置中也可以设置,一般默认的就足够了) | bin log 可通过配置参数max_bin log_size设置每个bin log文件的大小(但是一般不建议修改)。 |
| 实现方式 | redo log是InnoDB引擎层实现的(也就是说是 Innodb 存储引起过独有的) | bin log是 MySQL 层实现的,所有引擎都可以使用 bin log日志 |
| 记录方式 | redo log 采用循环写的方式记录,当写到结尾时,会回到开头循环写日志。 | bin log 通过追加的方式记录,当文件大小大于给定值后,后续的日志会记录到新的文件上 |
| 使用场景 | redo log适用于崩溃恢复(crash-safe)(这一点其实非常类似与 Redis 的持久化特征) | bin log适用于主从复制和数据恢复 |
bin log 记录的是整个操作记录(这个对于主从复制具有非常重要的意义)
以上就是执行一句SQL的情况的详细内容,更多请关注www.sxiaw.com其它相关文章!