优化 Go 中的内存使用:掌握数据结构对齐
内存优化对于编写高性能软件系统至关重要。当软件可使用的内存量有限时,如果内存未得到有效利用,就会出现许多问题。这就是为什么内存优化对于更好的整体性能至关重要。
go 继承了 c++ 的许多优势特性,但我注意到,很大一部分使用它的人并不了解这种语言的全部功能。原因之一可能是缺乏对它在低层次上如何工作的了解,或者缺乏使用 c 或 c++ 等语言的经验。我提到 c 和 c++ 是因为 go 的基础几乎是建立在 c/c++ 的出色功能之上的。我引用 ken thompson 在 google i/o 2012 上的采访绝非偶然:
对我来说,我对 go 充满热情的原因是因为就在我们开始使用 go 的同时,我阅读(或尝试阅读)c++0x 提议的标准,那是一个我的说服者。
今天,我们将讨论如何优化我们的 go 程序,更具体地说,是如何在 go 中使用结构体。我们先说一下什么是结构体:
结构体是一种用户定义的数据类型,它将不同类型的相关变量分组在一个名称下。
为了充分理解问题所在,我们将提到现代处理器一次不会从内存中读取 1 个字节。 cpu如何获取存储在内存中的数据或指令?
在计算机体系结构中,字是处理器可以在单个操作中处理的数据单元 - 通常是内存的最小可寻址单元。它是固定大小的位组(二进制数字)。处理器的字长决定了其有效处理数据的能力。常见的字长包括 8 位、16 位、32 位和 64 位。一些计算机处理器架构支持半字(即一个字中位数的一半)和双字(即两个连续的字)。
当今最常见的架构是 32 位和 64 位。如果您有 32 位处理器,则意味着它一次可以访问 4 个字节,这意味着字大小为 4 个字节。如果您有 64 位处理器,它一次可以访问 8 个字节,这意味着字大小为 8 个字节。
当我们将数据存储在内存中时,每个32位数据字都有一个唯一的地址,如下所示。
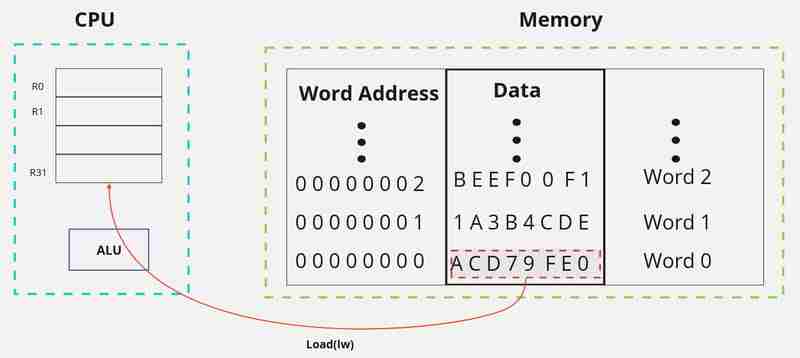
图。 1 ‑ 字可寻址存储器
我们可以读取内存中的数据,并使用加载字(lw)指令将其加载到一个寄存器。
了解了上面的理论之后,我们来看看实践是什么。对于结构数据结构的描述,我将用c语言进行演示。 c 中的结构是一种复合数据类型,允许您将多个变量组合在一起并将它们存储在同一内存块中。正如我们之前所说,cpu 访问数据取决于给定的架构。 c 中的每种数据类型都有对齐要求。
所以我们有以下简单结构:
// structure 1 typedef struct example_1 { char c; short int s; } struct1_t; // structure 2 typedef struct example_2 { double d; int s; char c; } struct2_t;
现在尝试计算以下结构的大小:
结构 1 的大小 = (char + short int) 的大小 = 1 + 2 = 3.
结构 2 的大小 = (double + int + char) 的大小 = 8 + 4 + 1= 13.
使用 c 程序的实际大小可能会让您大吃一惊。
#include <stdio.h> // structure 1 typedef struct example_1 { char c; short int s; } struct1_t; // structure 2 typedef struct example_2 { double d; int s; char c; } struct2_t; int main() { printf("sizeof(struct1_t) = %lu ", sizeof(struct1_t)); printf("sizeof(struct2_t) = %lu ", sizeof(struct2_t)); return 0; }
输出
sizeof(struct1_t) = 4 sizeof(struct2_t) = 16
正如我们所看到的,结构的大小与我们计算的不同。
这是什么原因呢?
c 和 go 采用一种称为“结构填充”的技术来确保数据在内存中适当对齐,由于硬件和架构的限制,这可能会显着影响性能。数据填充和对齐符合系统架构的要求,主要是通过确保数据边界与字长对齐来优化cpu访问时间。
让我们通过一个示例来说明 go 如何处理填充和对齐,请考虑以下结构:
type employee struct { isadmin bool id int64 age int32 salary float32 }
bool 为 1 个字节,int64 为 8 个字节,int32 为 4 个字节,float32 为 4 个字节 = 17 个字节(总计)。
让我们通过检查编译的 go 程序来验证结构大小:
package main
import (
"fmt"
"unsafe"
)
type employee struct {
isadmin bool
id int64
age int32
salary float32
}
func main() {
var emp employee
fmt.printf("size of employee: %d
", unsafe.sizeof(emp))
}
输出
size of employee: 24
报告的大小是 24 字节,而不是 17。这种差异是由于内存对齐造成的。要了解对齐的工作原理,我们需要检查结构并可视化它占用的内存。
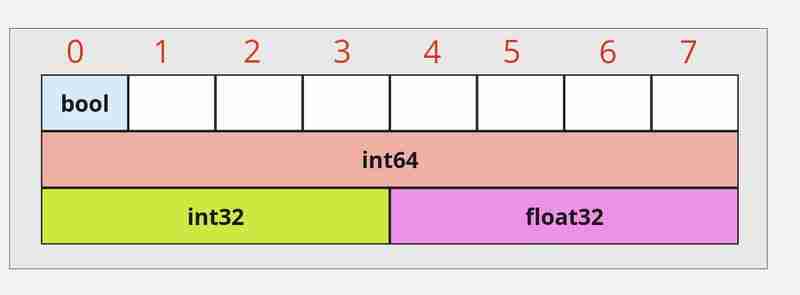
图 2 - 未优化的内存布局
struct employee 将消耗 8*3 = 24 个字节。你现在看到问题了,employee的布局中有很多空洞(那些由对齐规则产生的间隙称为“填充”)。
填充优化和性能影响
了解内存对齐和填充如何影响应用程序的性能至关重要。具体来说,数据对齐会影响访问结构体中的字段所需的 cpu 周期数。这种影响主要来自 cpu 缓存效应,而不是原始时钟周期本身,因为缓存行为很大程度上取决于内存块内的数据局部性和对齐。
现代 cpu 将数据从内存提取到更快的中介(称为缓存)中,以固定大小的块(通常为 64 字节)组织。当数据在相同或更少的缓存行中良好对齐和本地化时,由于缓存加载操作减少,cpu 可以更快地访问它。
考虑以下 go 结构来说明较差对齐与最佳对齐:
// poorly aligned struct type misaligned struct { age uint8 // uses 1 byte, followed by 7 bytes of padding to align the next field passportid uint64 // 8-byte aligned uint64 for the passport id children uint16 //2-byte aligned uint16 // well-aligned struct type aligned struct { age uint8 // starting with 1 byte children uint16 // next, 2 bytes; all these combine into a 3-byte sequence passportid uint64 // finally, an 8-byte aligned uint64 without needing additional padding }
对齐如何影响性能
cpu 以字大小而不是字节大小读取数据。正如我在开头所描述的,64 位系统中的一个字是 8 个字节,而 32 位系统中的一个字是 4 个字节。简而言之,cpu 以字大小的倍数读取地址。为了获取变量 passportid,我们的 cpu 需要两个周期来访问数据,而不是一个。第一个周期将获取内存 0 到 7,后续周期将获取其余内存。这是低效的——我们需要数据结构对齐。通过简单地对齐数据,计算机确保可以在一个cpu周期内检索到var passportid。
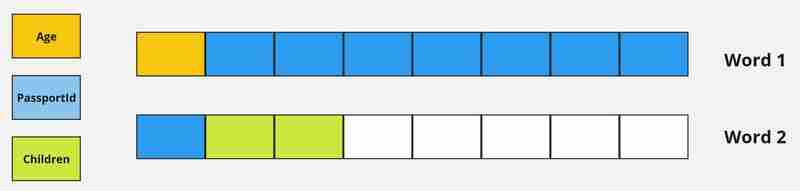
图 3 - 比较内存访问效率
padding是实现数据对齐的关键。之所以会发生填充,是因为现代 cpu 经过优化,可以从内存中的对齐地址读取数据。这种对齐方式允许 cpu 在单个操作中读取数据。
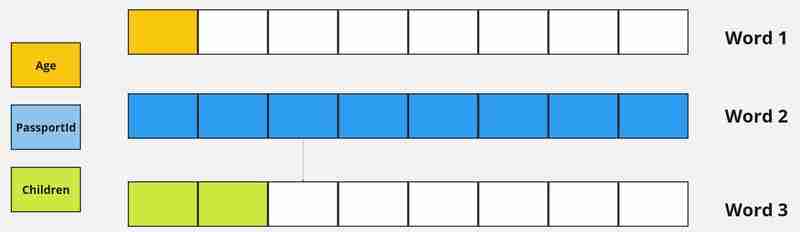
图 4 - 简单对齐数据
如果没有填充,数据可能会错位,导致多次内存访问和性能下降。因此,虽然 padding 可能会浪费一些内存,但它可以确保您的程序高效运行。
填充优化策略
对齐结构消耗更少的内存,因为与未对齐结构相比,它具有更好的结构字段顺序。由于填充,两个 13 字节的数据结构分别变为 16 字节和 24 字节。因此,只需重新排序结构字段即可节省额外的内存。
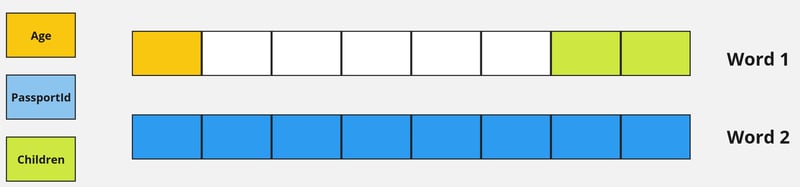
图 5 - 优化现场秩序
不正确对齐的数据会降低性能,因为 cpu 可能需要多个周期来访问未对齐的字段。相反,正确对齐的数据可以最大限度地减少缓存行负载,这对于性能至关重要,尤其是在内存速度成为瓶颈的系统中。
让我们做一个简单的基准来证明这一点:
var alignedarr []aligned
var misalignedarr []misaligned
func init() {
const samplesize = 1000
alignedarr = make([]aligned, samplesize)
misalignedarr = make([]misaligned, samplesize)
for i := 0; i < samplesize; i++ {
alignedarr[i] = aligned{age: uint8(i % 256), siblings: uint16(i), children: uint64(i)}
misalignedarr[i] = misaligned{age: uint8(i % 256), passportid: uint64(i), children: uint16(i)}
}
}
func traversealigned() uint16 {
var arbitrarynum uint16
for _, item := range alignedarr {
arbitrarynum += item.siblings
}
return arbitrarynum
}
func traversemisaligned() uint16 {
var arbitrarynum uint16
for _, item := range misalignedarr {
arbitrarynum += item.children
}
return arbitrarynum
}
func benchmarktraversealigned(b *testing.b) {
for n := 0; n < b.n; n++ {
traversealigned()
}
}
func benchmarktraversemisaligned(b *testing.b) {
for n := 0; n < b.n; n++ {
traversemisaligned()
}
}
输出
go test -bench=. goos: linux goarch: amd64 pkg: test-project cpu: 11th gen intel(r) core(tm) i9-11950h @ 2.60ghz benchmarktraversealigned-16 3022234 403.7 ns/op benchmarktraversemisaligned-16 4300167 299.1 ns/op pass ok test-project 3.195s
正如你所看到的,遍历 aligned 确实比遍历 aligned 花费的时间更少。
添加填充是为了确保每个结构体字段根据其需要在内存中正确排列,就像我们之前看到的那样。但是,虽然它可以实现高效访问,但如果字段排序不好,填充也会浪费空间。
了解如何正确对齐结构体字段以最大程度地减少填充导致的内存浪费对于高效内存使用非常重要,尤其是在性能关键型应用程序中。下面,我将提供一个结构对齐不良的示例,然后展示相同结构的优化版本。
在对齐不良的结构中,字段的排序不考虑其大小和对齐要求,这可能导致增加填充和增加内存使用量:
// badly aligned structure type person struct { active bool // 1 byte + 7 bytes padding salary float64 // 8 bytes age int32 // 4 bytes + 4 bytes padding nickname string // 16 bytes (string is typically 16 bytes on a 64-bit system) }
总内存可能是 1 (bool) + 7 (padding) + 8 (float64) + 4 (int32) + 4 (padding) + 16 (string) = 40 字节。
优化的结构按从最大到最小的顺序排列字段,显着减少或消除对额外填充的需要:
// well-aligned structure type person struct { salary float64 // 8 bytes nickname string // 16 bytes age int32 // 4 bytes active bool // 1 byte + 3 bytes padding }
总内存将整齐地包含 8 (float64) + 16 (string) + 4 (int32) + 1 (bool) + 3 (padding) = 32 字节。
我们来证明一下上面的内容:
package main
import (
"fmt"
"unsafe"
)
type poorlyalignedperson struct {
active bool
salary float64
age int32
nickname string
}
type wellalignedperson struct {
salary float64
nickname string
age int32
active bool
}
func main() {
poorlyaligned := poorlyalignedperson{}
wellaligned := wellalignedperson{}
fmt.printf("size of poorlyalignedperson: %d bytes
", unsafe.sizeof(poorlyaligned))
fmt.printf("size of wellalignedperson: %d bytes
", unsafe.sizeof(wellaligned))
}
输出
Size of PoorlyAlignedPerson: 40 bytes Size of WellAlignedPerson: 32 bytes
将结构大小从 40 字节减少到 32 字节意味着每个 person 实例的内存使用量减少 20%。这可以在创建或存储许多此类实例的应用程序中节省大量成本,提高缓存效率并有可能减少缓存未命中的数量。
结论
数据对齐是优化内存利用率和增强系统性能的关键因素。通过正确排列结构数据,内存使用不仅变得更加高效,而且 cpu 读取时间也变得更快,从而显着提高整体系统效率。
以上就是优化 Go 中的内存使用:掌握数据结构对齐的详细内容,更多请关注其它相关文章!