pytorch模型保存与加载中的一些问题实战记录
本篇文章给大家带来了关于Python的相关知识,其中主要介绍了关于pytorch模型保存与加载中的一些问题实战记录,下面一起来看一下,希望对大家有帮助。

【相关推荐:Python3视频教程 】
一、torch中模型保存和加载的方式
1、模型参数和模型结构保存和加载
torch.save(model,path) torch.load(path)
2、只保存模型的参数和加载——这种方式比较安全,但是比较稍微麻烦一点点
torch.save(model.state_dict(),path) model_state_dic = torch.load(path) model.load_state_dic(model_state_dic)
二、torch中模型保存和加载出现的问题
1、单卡模型下保存模型结构和参数后加载出现的问题
模型保存的时候会把模型结构定义文件路径记录下来,加载的时候就会根据路径解析它然后装载参数;当把模型定义文件路径修改以后,使用torch.load(path)就会报错。
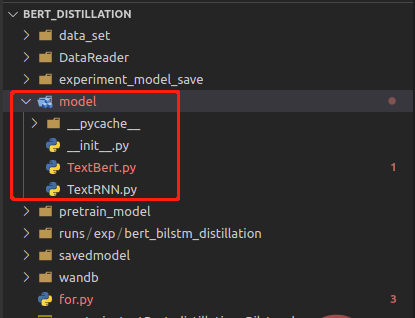
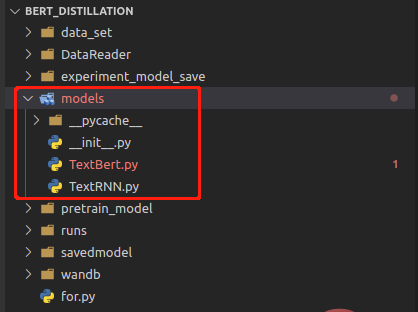

把model文件夹修改为models后,再加载就会报错。
import torch from model.TextRNN import TextRNN load_model = torch.load('experiment_model_save/textRNN.bin') print('load_model',load_model)
这种保存完整模型结构和参数的方式,一定不要改动模型定义文件路径。
2、多卡机器单卡训练模型保存后在单卡机器上加载会报错
在多卡机器上有多张显卡0号开始,现在模型在n>=1上的显卡训练保存后,拷贝在单卡机器上加载
import torch from model.TextRNN import TextRNN load_model = torch.load('experiment_model_save/textRNN_cuda_1.bin') print('load_model',load_model)
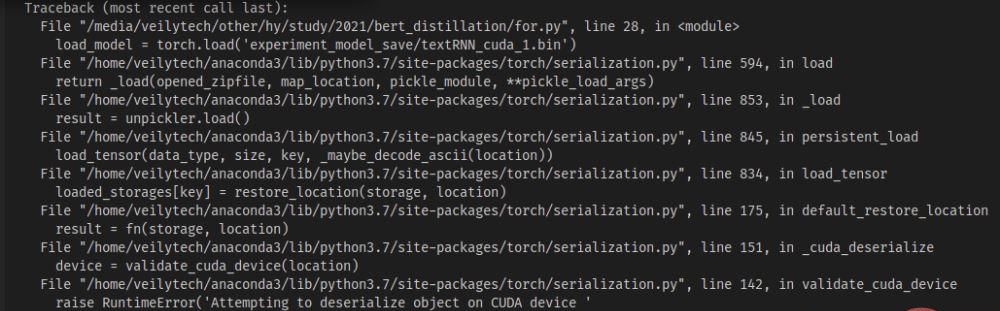
会出现cuda device不匹配的问题——你保存的模代码段 小部件型是使用的cuda1,那么采用torch.load()打开的时候,会默认的去寻找cuda1,然后把模型加载到该设备上。这个时候可以直接使用map_location来解决,把模型加载到CPU上即可。
load_model = torch.load('experiment_model_save/textRNN_cuda_1.bin',map_location=torch.device('cpu'))
3、多卡训练模型保存模型结构和参数后加载出现的问题
当用多GPU同时训练模型之后,不管是采用模型结构和参数一起保存还是单独保存模型参数,然后在单卡下加载都会出现问题
a、模型结构和参数一起保然后在加载

torch.distributed.init_process_group(backend='nccl')
模型训练的时候采用上述多进程的方式,所以你在加载的时候也要声明,不然就会报错。
b、单独保存模型参数
model = Transformer(num_encoder_layers=6,num_decoder_layers=6) state_dict = torch.load('train_model/clip/experiment.pt') model.load_state_dict(state_dict)
同样会出现问题,不过这里出现的问题是参数字典的key和模型定义的key不一样

原因是多GPU训练下,使用分布式训练的时候会给模型进行一个包装,代码如下:
model = torch.load('train_model/clip/Vtransformers_bert_6_layers_encoder_clip.bin') print(model) model.cuda(args.local_rank) 。。。。。。 model = nn.parallel.DistributedDataParallel(model,device_ids=[args.local_rank],find_unused_parameters=True) print('model',model)
包装前的模型结构:
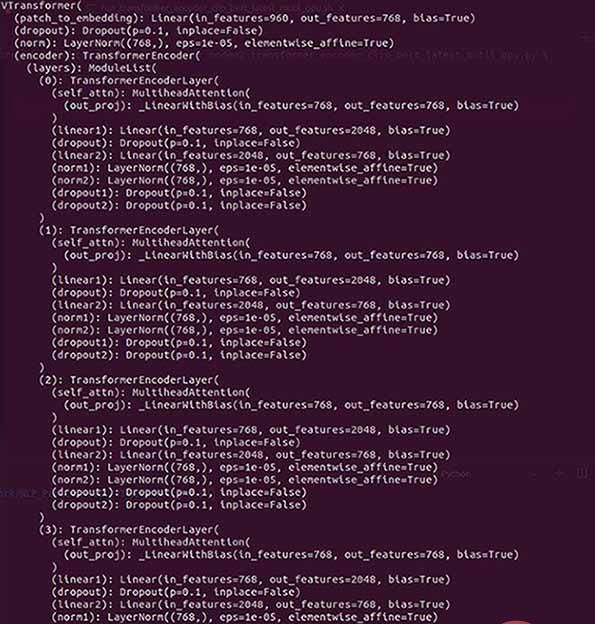
包装后的模型
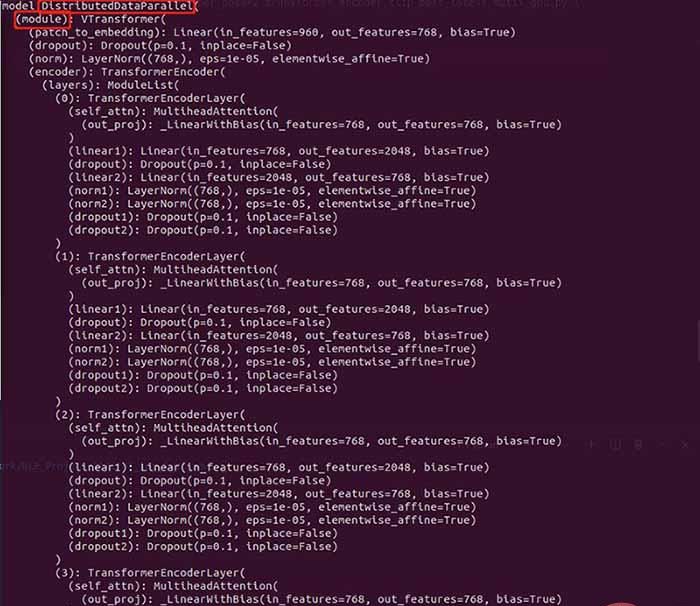
在外层多了DistributedDataParallel以及module,所以才会导致在单卡环境下加载模型权重的时候出现权重的keys不一致。
三、正确的保存模型和加载的方法
if gpu_count > 1:
torch.save(model.module.state_dict(),save_path)
else:
torch.save(model.state_dict(),save_path)
model = Transformer(num_encoder_layers=6,num_decoder_layers=6)
state_dict = torch.load(save_path)
model.load_state_dict(state_dict)这样就是比较好的范式,加载不会出错。
【相关推荐:Python3视频教程 】
以上就是pytorch模型保存与加载中的一些问题实战记录的详细内容,更多请关注其它相关文章!