用Python爬了我的微信好友,他们是这样的...

随着微信的普及,越来越多的人开始使用微信。微信渐渐从一款单纯的社交软件转变成了一个生活方式,人们的日常沟通需要微信,工作交流也需要微信。微信里的每一个好友,都代表着人们在社会里扮演的不同角色。

今天这篇文章会基于Python对微信好友进行数据分析,这里选择的维度主要有:性别、头像、签名、位置,主要采用图表和词云两种形式来呈现结果,其中,对文本类信息会采用词频分析和情感分析两种方法。常言道:工欲善其事,必先利其器也。在正式开始这篇文章前,简单介绍下本文中使用到的第三方模块:
itchat:微信网页版接口封装Python版本,在本文中用以获取微信好友信息。
jieba:结巴分词的 Python 版本,在本文中用以对文本信息进行分词处理。
matplotlib:Python 中图表绘制模块,在本文中用以绘制柱形图和饼图
snownlp:一个 Python 中的中文分词模块,在本文中用以对文本信息进行情感判断。
PIL:Python 中的图像处理模块,在本文中用以对图片进行处理。
numpy:Python中 的数值计算模块,在本文中配合 wordcloud 模块使用。
wordcloud:Python 中的词云模块,在本文中用以绘制词云图片。
TencentYoutuyun:腾讯优图提供的 Python 版本 SDK ,在本文中用以识别人脸及提取图片标签信息。
以上模块均可通过 pip 安装,关于各个模块使用的详细说明,请自行查阅各自文档。
1. 数据分析
分析微信好友数据的前提是获得好友信息,通过使用 itchat 这个模块,这一切会变得非常简单,我们通过下面两行代码就可以实现:
itchat.auto_login(hotReload = True) friends = itchat.get_friends(update = True)
同平时登录网页版微信一样,我们使用手机扫描二维码就可以登录,这里返回的friends对象是一个集合,第一个元素是当前用户。所以,在下面的数据分析流程中,我们始终取friends[1:]作为原始输入数据,集合中的每一个元素都是一个字典结构,以我本人为例,可以注意到这里有Sex、City、Province、HeadImgUrl、Signature这四个字段,我们下面的分析就从这四个字段入手:

2. 好友性别
分析好友性别,我们首先要获得所有好友的性别信息,这里我们将每一个好友信息的Sex字段提取出来,然后分别统计出Male、Female和Unkonw的数目,我们将这三个数值组装到一个列表中,即可使用matplotlib模块绘制出饼图来,其代码实现如下:
def analyseSex(firends): sexs = list(map(lambda x:x['Sex'],friends[1:])) counts = list(map(lambda x:x[1],Counter(sexs).items())) labels = ['Unknow','Male','Female'] colors = ['red','yellowgreen','lightskyblue'] plt.figure(figsize=(8,5), dpi=80) plt.axes(aspect=1) plt.pie(counts, #性别统计结果 labels=labels, #性别展示标签 colors=colors, #饼图区域配色 labeldistance = 1.1, #标签距离圆点距离 autopct = '%3.1f%%', #饼图区域文本格式 shadow = False, #饼图是否显示阴影 startangle = 90, #饼图起始角度 pctdistance = 0.6 #饼图区域文本距离圆点距离 ) plt.legend(loc='upper right',) plt.title(u'%s的微信好友性别组成' % friends[0]['NickName']) plt.show()
这里简单解释下这段代码,微信中性别字段的取值有Unkonw、Male和Female三种,其对应的数值分别为0、1、2。通过Collection模块中的Counter()对这三种不同的取值进行统计,其items()方法返回的是一个元组的集合。
该元组的第一维元素表示键,即0、1、2,该元组的第二维元素表示数目,且该元组的集合是排序过的,即其键按照0、1、2 的顺序排列,所以通过map()方法就可以得到这三种不同取值的数目,我们将其传递给matplotlib绘制即可,这三种不同取值各自所占的百分比由matplotlib计算得出。下图是matplotlib绘制的好友性别分布图:
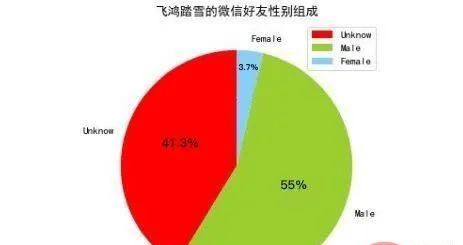
3. 好友头像
分析好友头像,从两个方面来分析,第一,在这些好友头像中,使用人脸头像的好友比重有多大;第二,从这些好友头像中,可以提取出哪些有价值的关键字。
这里需要根据HeadImgUrl字段下载头像到本地,然后通过腾讯优图提供的人脸识别相关的API接口,检测头像图片中是否存在人脸以及提取图片中的标签。其中,前者是分类汇总,我们使用饼图来呈现结果;后者是对文本进行分析,我们使用词云来呈现结果。关键代码如下所示:
def analyseHeadImage(frineds):
# Init Path
basePath = os.path.abspath('.')
baseFolder = basePath + '\HeadImages\'
if(os.path.exists(baseFolder) == False):
os.makedirs(baseFolder)
# Analyse Images
faceApi = FaceAPI()
use_face = 0
not_use_face = 0
image_tags = ''
for index in range(1,len(friends)):
friend = friends[index]
# Save HeadImages
imgFile = baseFolder + '\Image%s.jpg' % str(index)
imgData = itchat.get_head_img(userName = friend['UserName'])
if(os.path.exists(imgFile) == False):
with open(imgFile,'wb') as file:
file.write(imgData)
# Detect Faces
time.sleep(1)
result = faceApi.detectFace(imgFile)
if result == True:
use_face += 1
else:
not_use_face += 1
# Extract Tags
result = faceApi.extractTags(imgFile)
image_tags += ','.join(list(map(lambda x:x['tag_name'],result)))
labels = [u'使用人脸头像',u'不使用人脸头像']
counts = [use_face,not_use_face]
colors = ['red','yellowgreen','lightskyblue']
plt.figure(figsize=(8,5), dpi=80)
plt.axes(aspect=1)
plt.pie(counts, #性别统计结果
labels=labels, #性别展示标签
colors=colors, #饼图区域配色
labeldistance = 1.1, #标签距离圆点距离
autopct = '%3.1f%%', #饼图区域文本格式
shadow = False, #饼图是否显示阴影
startangle = 90, #饼图起始角度
pctdistance = 0.6 #饼图区域文本距离圆点距离
)
plt.legend(loc='upper right',)
plt.title(u'%s的微信好友使用人脸头像情况' % friends[0]['NickName'])
plt.show()
image_tags = image_tags.encode('iso8859-1').decode('utf-8')
back_coloring = np.array(Image.open('face.jpg'))
wordcloud = WordCloud(
font_path='simfang.ttf',
background_color="white",
max_words=1200,
mask=back_coloring,
max_font_size=75,
random_state=45,
width=800,
height=480,
margin=15
)
wordcloud.generate(image_tags)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()这里我们会在当前目录新建一个HeadImages目录,用于存储所有好友的头像,然后我们这里会用到一个名为FaceApi类,这个类由腾讯优图的SDK封装而来,这里分别调用了人脸检测和图像标签识别两个API接口,前者会统计”使用人脸头像”和”不使用人脸头像”的好友各自的数目,后者会累加每个头像中提取出来的标签。其分析结果如下图所示:
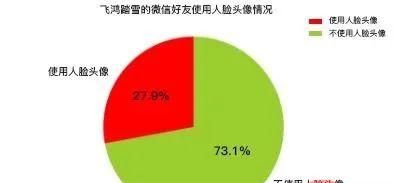
可以注意到,在所有微信好友中,约有接近1/4的微信好友使用了人脸头像, 而有接近3/4的微信好友没有人脸头像,这说明在所有微信好友中对”颜值 “有自信的人,仅仅占到好友总数的25%,或者说75%的微信好友行事风格偏低调为主,不喜欢用人脸头像做微信头像。
其次,考虑到腾讯优图并不能真正的识别”人脸”,我们这里对好友头像中的标签再次进行提取,来帮助我们了解微信好友的头像中有哪些关键词,其分析结果如图所示:

通过词云,我们可以发现:在微信好友中的签名词云中,出现频率相对较高的关键字有:女孩、树木、房屋、文本、截图、卡通、合影、天空、大海。这说明在我的微信好友中,好友选择的微信头像主要有日常、旅游、风景、截图四个来源。
好友选择的微信头像中风格以卡通为主,好友选择的微信头像中常见的要素有天空、大海、房屋、树木。通过观察所有好友头像,我发现在我的微信好友中,使用个人照片作为微信头像的有15人,使用网络图片作为微信头像的有53人,使用动漫图片作为微信头像的有25人,使用合照图片作为微信头像的有3人,使用孩童照片作为微信头像的有5人,使用风景图片作为微信头像的有13人,使用女孩照片作为微信头像的有18人,基本符合图像标签提取的分析结果。
4. 好友签名
分析好友签名,签名是好友信息中最为丰富的文本信息,按照人类惯用的”贴标签”的方法论,签名可以分析出某一个人在某一段时间里状态,就像人开心了会笑、哀伤了会哭,哭和笑两种标签,分别表明了人开心和哀伤的状态。
这里我们对签名做两种处理,第一种是使用结巴分词进行分词后生成词云,目的是了解好友签名中的关键字有哪些,哪一个关键字出现的频率相对较高;第二种是使用SnowNLP分析好友签名中的感情倾向,即好友签名整体上是表现为正面的、负面的还是中立的,各自的比重是多少。这里提取Signature字段即可,其核心代码如下:
def analyseSignature(friends):
signatures = ''
emotions = []
pattern = re.compile("1fd.+")
for friend in friends:
signature = friend['Signature']
if(signature != None):
signature = signature.strip().replace('span', '').replace('class', '').replace('emoji', '')
signature = re.sub(r'1f(d.+)','',signature)
if(len(signature)>0):
nlp = SnowNLP(signature)
emotions.append(nlp.sentiments)
signatures += ' '.join(jieba.analyse.extract_tags(signature,5))
with open('signatures.txt','wt',encoding='utf-8') as file:
file.write(signatures)
# Sinature WordCloud
back_coloring = np.array(Image.open('flower.jpg'))
wordcloud = WordCloud(
font_path='simfang.ttf',
background_color="white",
max_words=1200,
mask=back_coloring,
max_font_size=75,
random_state=45,
width=960,
height=720,
margin=15
)
wordcloud.generate(signatures)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
wordcloud.to_file('signatures.jpg')
# Signature Emotional Judgment
count_good = len(list(filter(lambda x:x>0.66,emotions)))
count_normal = len(list(filter(lambda x:x>=0.33 and x<=0.66,emotions)))
count_bad = len(list(filter(lambda x:x<0.33,emotions)))
labels = [u'负面消极',u'中性',u'正面积极']
values = (count_bad,count_normal,count_good)
plt.rcParams['font.sans-serif'] = ['simHei']
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel(u'情感判断')
plt.ylabel(u'频数')
plt.xticks(range(3),labels)
plt.legend(loc='upper right',)
plt.bar(range(3), values, color = 'rgb')
plt.title(u'%s的微信好友签名信息情感分析' % friends[0]['NickName'])
plt.show()通过词云,我们可以发现:在微信好友的签名信息中,出现频率相对较高的关键词有:努力、长大、美好、快乐、生活、幸福、人生、远方、时光、散步。

通过以下柱状图,我们可以发现:在微信好友的签名信息中,正面积极的情感判断约占到55.56%,中立的情感判断约占到32.10%,负面消极的情感判断约占到12.35%。这个结果和我们通过词云展示的结果基本吻合,这说明在微信好友的签名信息中,约有87.66%的签名信息,传达出来都是一种积极向上的态度。
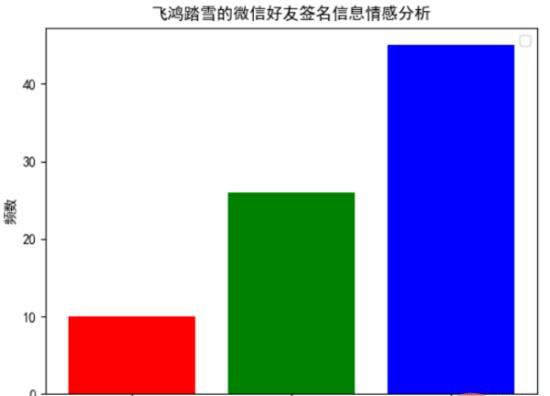
5. 好友位置
分析好友位置,主要通过提取Province和City这两个字段。Python中的地图可视化主要通过Basemap模块,这个模块需要从国外网站下载地图信息,使用起来非常的不便。
百度的ECharts在前端使用的比较多,虽然社区里提供了pyecharts项目,可我注意到因为政策的改变,目前Echarts不再支持导出地图的功能,所以地图的定制方面目前依然是一个问题,主流的技术方案是配置全国各省市的JSON数据。
这里我使用的是BDP个人版,这是一个零编程的方案,我们通过Python导出一个CSV文件,然后将其上传到BDP中,通过简单拖拽就可以制作可视化地图,简直不能再简单,这里我们仅仅展示生成CSV部分的代码:
def analyseLocation(friends):
headers = ['NickName','Province','City']
with open('location.csv','w',encoding='utf-8',newline='',) as csvFile:
writer = csv.DictWriter(csvFile, headers)
writer.writeheader()
for friend in friends[1:]:
row = {}
row['NickName'] = friend['NickName']
row['Province'] = friend['Province']
row['City'] = friend['City']
writer.writerow(row)下图是BDP中生成的微信好友地理分布图,可以发现:我的微信好友主要集中在宁夏和陕西两个省份。
6. 总结
这篇文章是我对数据分析的又一次尝试,主要从性别、头像、签名、位置四个维度,对微信好友进行了一次简单的数据分析,主要采用图表和词云两种形式来呈现结果。总而言之一句话,”数据可视化是手段而并非目的”,重要的不是我们在这里做了这些图出来,而是从这些图里反映出来的现象,我们能够得到什么本质上的启示,希望这篇文章能让大家有所启发。
以上就是用Python爬了我的微信好友,他们是这样的...的详细内容,更多请关注其它相关文章!