redis主从同步原理

1.前言
在redis中为了保证redis的高可用,一般会搭建一种集群模式就是主从模式。
主从模式可以保证redis的高可用,那么redis是怎么保证主从服务器的数据一致性的,接下来我们浅谈下redis主(master)从(slave)同步的原理。
2.初次全量同步
当一个redis服务器初次向主服务器发送salveof命令时,redis从服务器会进行一次全量同步,同步的步骤如下图所示:
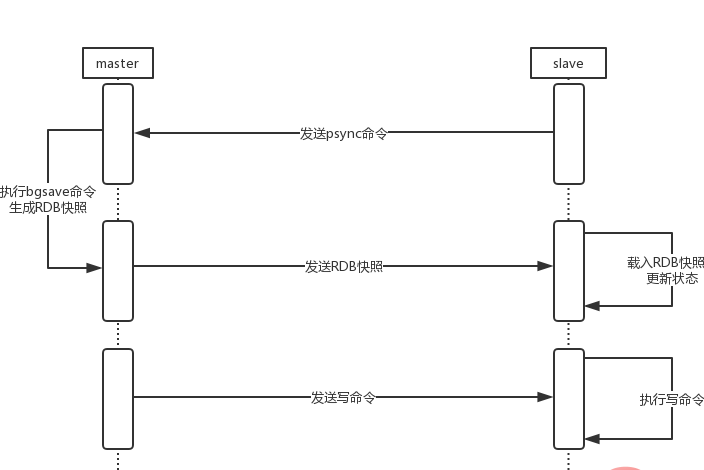
- slave服务器向master发送psync命令(此时发送的是psync ? -1),告诉master我需要同步数据了。
- master接收到psync命令后会进行BGSAVE命令生成RDB文件快照。
- 生成完后,会将RDB文件发送给slave。
- slave接收到文件会载入RDB快照,并且将数据库状态变更为master在执行BGSAVE时的状态一致。
- master会发送保存在缓冲区里的所有写命令,告诉slave可以进行同步了
- slave执行这些写命令。
3.命令传播
slave已经同步过master了,那么如果后续master进行了写操作,比如说一个简单的set name redis,那么master执行过当前命令后,会将当前命令发送给slave执行一遍,达成数据一致性。
4.重新复制
当slave断开重连之后会进行重新同步,重新同步分完全同步和部分同步
首先来看看部分同步大致的走向
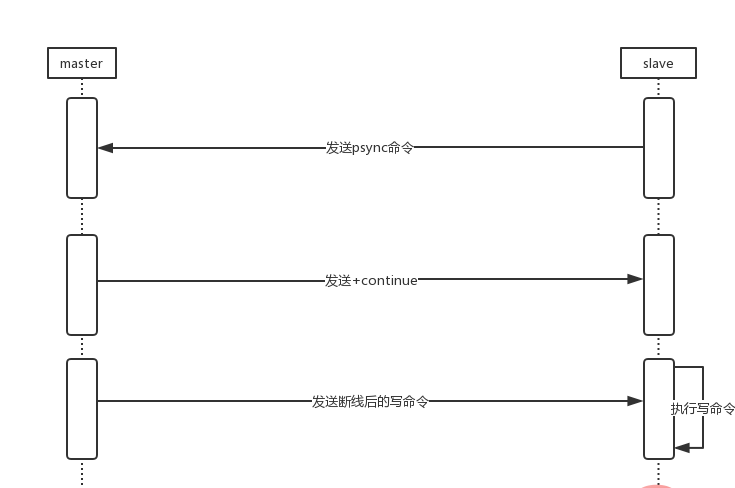
- 当slave断开重连后,会发送psync 命令给master。
- master收到psync后会返回+continue回复,表示slave可以执行部分同步了。
- master发送断线后的写命令给slave
- slave执行写命令。
实际上当slave发送psync命令给master之后,master还需要根据以下三点判断是否进行部分同步。
先来介绍一下是哪三个方面:
- 服务器运行ID
每个redis服务器开启后会生成运行ID。
当进行初次同步时,master会将自己的ID告诉slave,slave会记录下来,当slave断线重连后,发现ID是这个master的就会尝试进行部分重同步。当ID与现在连接的master不一样时会进行完整重同步。
- 复制偏移量
复制偏移量包括master复制偏移量和slave复制偏移量,当初次同步过后两个数据库的复制偏移量相同,之后master执行一次写命令,那么master的偏移量+1,master将写命令给slave,slave执行一次,slave偏移量+1,这样版本就能一致。
- 复制积压缓冲区
复制积压缓冲区是由master维护的固定长度的先进先出的队列。
当slave发送psync,会将自己的偏移量也发送给master,当slave的偏移量之后的数据在缓冲区还存在,就会返回+continue通知slave进行部分重同步。
当slave的偏移量之后的数据不在缓冲区了,就会进行完整重同步。
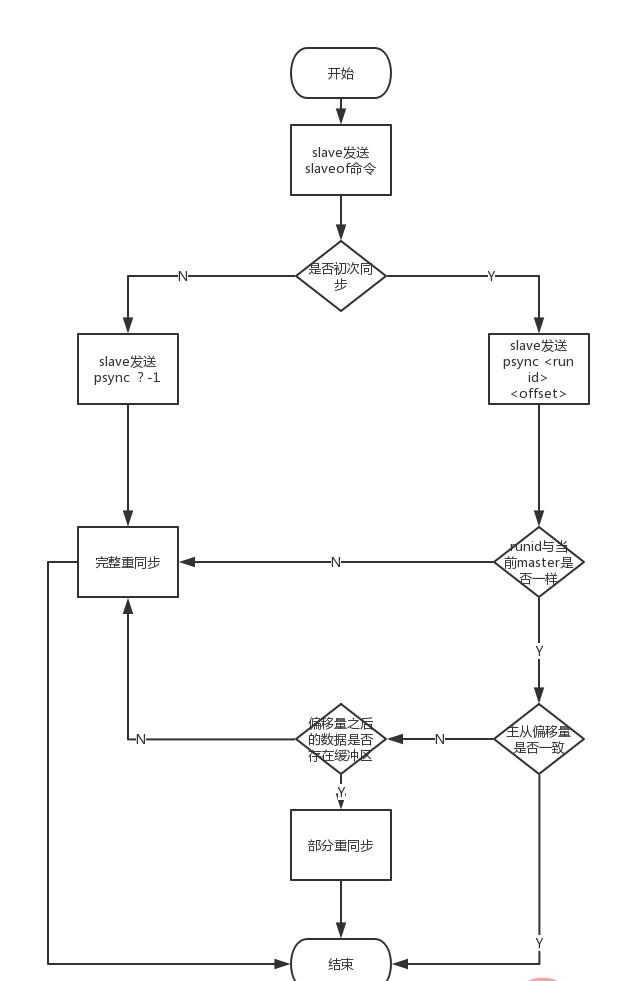
结合以上三点,我们又可以总结下:
- 当slave断开重连后,会发送psync 命令给master。
- master首先会对服务器运行id进行判断,如果与自己相同就进行判断偏移量
- master会判断自己的偏移量与slave的偏移量是否一致。
- 如果不一致,master会去缓冲区中判断slave的偏移量之后的数据是否存在。
- 如果存在就会返回+continue回复,表示slave可以执行部分同步了。
- master发送断线后的写命令给slave
- slave执行写命令。
5.主从同步最终流程
6.结语
最近公司需要,我搭建了一套redis主从集群并且用哨兵进行监听实现主从切换。因此我根据《redis设计与实现》梳理了redis主从原理,给自己加深印象。
推荐教程: 《redis教程》
以上就是redis主从同步原理的详细内容,更多请关注其它相关文章!