Java讲解ThreadPool线程池

ThreadPool线程池
- 1.线程池的优势
- 1.1.引言
- 1.2.为什么要使用线程池
- 2.线程池的使用
- 2.1.架构说明
- 2.2.线程池的三大方法
- 2.2.1.newFixedThreadPool(int)方法
- 2.2.2.newSingleThreadExector
- 2.2.3.newCachedThreadPool
- 3.ThreadPoolExecutor底层原理
- 4.线程池7大重要参数
(相关免费学习推荐:java基础教程)
1.线程池的优势
1.1.引言
与数据库线程池类似,如果没有数据库连接池,那么每次对数据库的连接池都要new来获取连接池。重复的连接和释放操作会消费大量的系统资源,我们可以使用数据库连接池,直接去池中取连接池。
同样,在没有线程池之前,我们也是通过new Thread.start()来获取线程,现在我们也不需要new了,这样就能实现复用,使得我们系统变得更加高效。
1.2.为什么要使用线程池
例子:
- 10年前单核CPU电脑,假的多线程,像马戏团小丑玩多个球,CPU需要来回切换。
- 现在是多核电脑,多个线程各自跑在独立的CPU上,不用切换效率高。
线程池的优势:
线程池做的工作只要是控制运行的线程数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量,超出数量的线程排队等候,等其他线程执行完毕,再从队列中取出任务来执行。
它的主要特点为:
- 线程复用
- 控制最大并发数
- 管理线程
优点:
- 第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的销耗。
- 第二:提高响应速度。当任务到达时,任务可以不需要等待线程创建就能立即执行。
- 第三:提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会销耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
2.线程池的使用
2.1.架构说明
Executor 框架是什么?
Java Doc中是这么描述的
An object that executes submitted Runnable tasks. This interface provides a way of decoupling task submission from the mechanics of how each task will be run, including details of thread use, scheduling, etc. An Executor is normally used instead of explicitly creating threads.
执行提交的Runnable任务的对象。这个接口提供了一种将任务提交与如何运行每个任务的机制,包括线程的详细信息使用、调度等。通常使用Executor而不是显式地创建线程。
Java中的线程池是通过Executor框架实现的,,该框架中用到了Executor,Executors,ExecutorService,ThreadPoolExecutor这几个类。而我们常用的接口是ExecutorService子接口,Executors是线程的工具类(类似数组的工具类Arrays,集合的工具类Collections)。ThreadPoolExecutor是这些类的重点。我们可以通过辅助工具类Executors拿到ThreadPoolExecutor线程池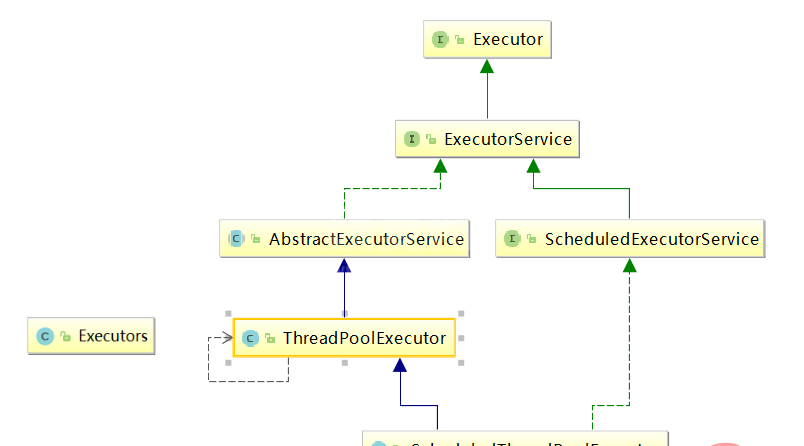
各个类更加详细的介绍如下:
Executor所有线程池的接口,只有一个方法,该接口定义执行Runnable任务的方式
ExecutorService 增加Executor的行为,是Executor实现类的最直接的接口,该接口定义提供对Executor的服务
Executors 线程池工厂类,提供了一系列工厂方法用于创建线程池,返回的线程池都实现了
ScheduledExecutorService:定时调度接口。
AbstractExecutorService 执行框架抽象类。
ThreadPoolExecutor JDK中线程池的具体实现,一般用的各种线程池都是基于这个类实现的
2.2.线程池的三大方法
2.2.1.newFixedThreadPool(int)方法
Exectors.newFixedThreadPool(int) -->执行长期任务性能好,创建一个线程池,一池有N个固定的线程,有固定线程数的线程
public static void main(String[] args) {
//一池5个受理线程,类似一个银行5个受理窗口。不管你现在多少个线程,都只有5个
ExecutorService threadPool=Executors.newFixedThreadPool(5);
try {
//模拟有10个顾客过来银行办理业务,目前池子里面有5个工作人员提供服务。
for(int i=1;i<=10;i++){
//execute方法里面有一个参数,参数类型是Runnable,Runnable是函数式接口,可以用lambda表达式,并且runnable就是这10个顾客
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName()+"\t 办理业务");
});
}
} catch (Exception e) {
// TODO: handle exception
}finally{
threadPool.shutdown();
}
}
可以看到执行结果。池子中有5个线程,相当于5个工作人员对外提供服务,办理业务。图中1号窗口办理了两次业务,银行的受理窗口可以多次被复用。也不一定是每个人办理两次,而是谁办理的快谁就办理的多。
当我们再线程执行的过程中加400ms的延迟,可以看看效果
public static void main(String[] args) {
//一池5个受理线程,类似一个银行5个受理窗口。不管你现在多少个线程,都只有5个
ExecutorService threadPool=Executors.newFixedThreadPool(5);
try {
//模拟有10个顾客过来银行办理业务,目前池子里面有5个工作人员提供服务。
for(int i=1;i<=10;i++){
//execute方法里面有一个参数,参数类型是Runnable,Runnable是函数式接口,可以用lambda表达式,并且runnable就是这10个顾客
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName()+"\t 办理业务");
});
try {
TimeUnit.MILLISECONDS.sleep(400);
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
} catch (Exception e) {
// TODO: handle exception
}finally{
threadPool.shutdown();
}
}
此时说明网络拥堵的情况下或者办理业务比较慢,则线程池办理业务任务分配情况比较平均。
2.2.2.newSingleThreadExector
Exectors.newSingleThreadExector()–>一个任务一个任务的执行,一池一线程
public static void main(String[] args) {
//一池一个工作线程,类似一个银行有1个受理窗口
ExecutorService threadPool=Executors.newSingleThreadExecutor();
try {
//模拟有10个顾客过来银行办理业务
for(int i=1;i<=10;i++){
//execute方法里面有一个参数,参数类型是Runnable,Runnable是函数式接口,可以用lambda表达式,并且runnable就是这10个顾客
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName()+"\t 办理业务");
});
}
} catch (Exception e) {
// TODO: handle exception
}finally{
threadPool.shutdown();
} }
2.2.3.newCachedThreadPool
Exectors.newCachedThreadPool()–>执行很多短期异步任务,线程池根据需要创建新线程,但在先前构建的线程可用时将重用他们。可扩容,遇强则强。一池n线程,可扩容,可伸缩,cache缓存的意思
那么池的数量应该设置多少呢,如果银行只有一个窗口,那么当人来得太多了,就忙不过来。如果银行有很多个窗口,但是人来的少,此时又显得浪费资源。那么如何该合理安排呢?这就需要用到newCachedThreadPool()方法,可扩容,可伸缩
public static void main(String[] args) {
//一池一个工作线程,类似一个银行有n个受理窗口
ExecutorService threadPool=Executors.newCachedThreadPool();
try {
//模拟有10个顾客过来银行办理业务
for(int i=1;i<=10;i++){
//execute方法里面有一个参数,参数类型是Runnable,Runnable是函数式接口,可以用lambda表达式,并且runnable就是这10个顾客
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName()+"\t 办理业务");
});
}
} catch (Exception e) {
// TODO: handle exception
}finally{
threadPool.shutdown();
}
}
public static void main(String[] args) {
//一池一个工作线程,类似一个银行有n个受理窗口
ExecutorService threadPool=Executors.newCachedThreadPool();
try {
//模拟有10个顾客过来银行办理业务
for(int i=1;i<=10;i++){
try{TimeUnit.SECONDS.sleep(1);}catch(InterruptedException e){e.printStackTrace();}
//execute方法里面有一个参数,参数类型是Runnable,Runnable是函数式接口,可以用lambda表达式,并且runnable就是这10个顾客
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName()+"\t 办理业务");
});
}
} catch (Exception e) {
// TODO: handle exception
}finally{
threadPool.shutdown();
}
}
3.ThreadPoolExecutor底层原理
newFixedThreadPool底层源代码
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}可以看到,底层的参数包含LinkedBlockingQueue阻塞队列。
newSingleThreadExecutor底层源代码
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}newCachedThreadPool底层源代码
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}SynchronousQueue这个阻塞队列是单一版阻塞队列,阻塞队列的容量为1.
这3个方法其实都共同返回了一个对象,即ThreadPoolExecutor的对象。
4.线程池7大重要参数
ThreadPoolExecutor的构造函数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}上面的int corePoolSize,int maximumPoolSize, long keepAliveTime, TimeUnit unit,BlockingQueue workQueue,ThreadFactory threadFactory,
RejectedExecutionHandler handler即我们的七大线程参数
上面是ThreadPoolExecutor类的构造方法,有7大参数:
1)corePoolSize:线程池中的常驻核心线程数,简称核心数。
比如说,一个线程池我们可以把它当作银行的网点,银行只要开门,就必须至少有一个人在值班,这个就叫常驻核心线程数。比如如果某个银行周一到周五五个网点全开,那么周一到周五的常驻核心线程数为5.如果今天业务没有那么频繁,窗口为1,那么今天的常驻核心线程数就是1
2)maxImumPoolSize:线程池中能够容纳同时执行的最大线程数,此值必须大于等于1
3)keepAliveTime:多余的空闲线程的存活时间,当前池中线程数量超过corePoolSize时,当空闲时间达到keepAliveTime时,多余线程会被销毁直到剩下corePoolSize为止
如果线程池中有常驻线程数,又有最大线程数,说明平时是用常驻的,工作紧张了,它会扩容到最大线程数,如果业务降下来了,我们设置了多余的空闲线程的存活时间,比如设置30s,如果30s都没有多余的请求过来,有些银行就会关闭窗口,所以它不仅会扩大还会缩小。
4)unit:keepAliveTime的单位
单位:是秒,毫秒,微秒。
5)workQueue:任务队列,被提交但尚未被执行的任务
这是一个阻塞队列,比如说银行,只有3个受理窗口,而来了4个客户。这个阻塞队列就是银行的候客区,来了客户不能让他走了。窗口数控制了线程的并发数。
6)threadFactory:表示生成线程池中工作线程的线程工厂,用于创建线程,一般默认即可
线程都是统一的创建。线程池里面有已经new好的线程,这些由线程池工厂生产。
7)handler:拒绝策略,表示当前队列满了,并且工作线程大于等于线程池的最大线程数(maximumPoolSize)时如何来拒绝请求执行的runnable的策略
比如说今天银行客流高峰,三个窗口都满了,候客区也满了。我们没有选择继续拉人,因为不安全我们选择委婉的拒绝。
在下一节我们将介绍线程池底层工作原理
相关学习推荐:java基础
以上就是Java讲解ThreadPool线程池的详细内容,更多请关注其它相关文章!