Entropix:最大化推理性能的采样技术
entropix:最大化推理性能的采样技术
根据 entropix readme,entropix 使用基于熵的采样方法。本文讲解了基于熵和变熵的具体采样技术。
熵和变熵
让我们首先解释一下熵和变熵,因为它们是决定采样策略的关键因素。
熵
在信息论中,熵是随机变量不确定性的度量。随机变量 x 的熵由以下等式定义:
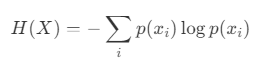
- x:离散随机变量。
- x_i:x 的第 i 个可能状态。
- p(x_i):状态 x_i 的概率。
当概率分布均匀时,熵最大化。相反,当特定状态比其他状态更有可能出现时,熵就会减少。
变熵
变熵与熵密切相关,代表信息内容的可变性。考虑到随机变量 x 的信息内容 i(x)、熵 h(x) 和方差,变熵 v e(x) 定义如下:
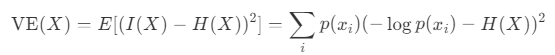
当概率 p(x_i) 变化很大时,变熵变大。当概率均匀时(无论是当分布具有最大熵时,还是当一个值的概率为 1 而所有其他值的概率为 0 时),它会变小。
抽样方法
接下来,让我们探讨一下采样策略如何根据熵和变熵值而变化。
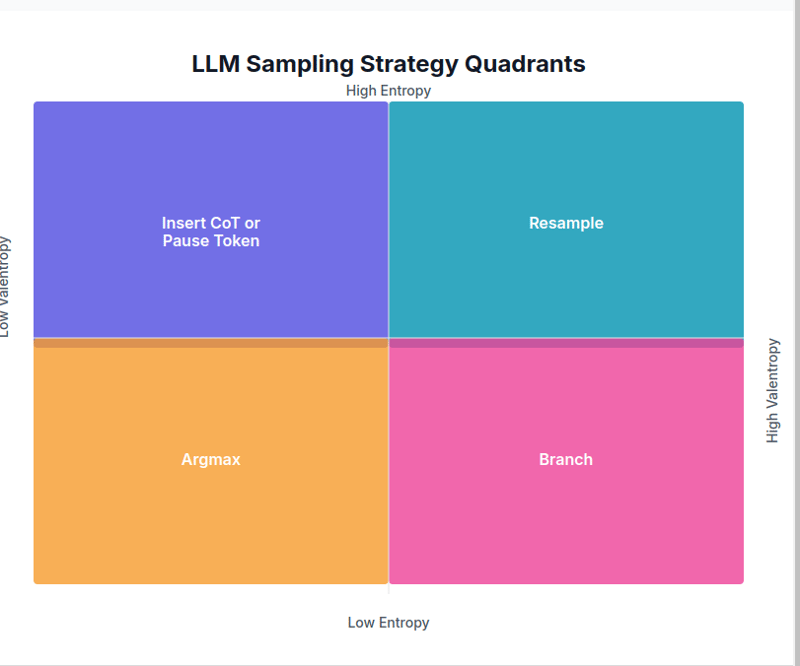
1. 低熵、低变熵 → argmax
在这种情况下,特定令牌的预测概率比其他令牌高得多。由于下一个标记几乎确定,因此使用 argmax。
if ent <p>代码链接</p> <h4> 2. 低熵、高变熵 → 分支 </h4> <p>当有一定的信心,但存在多种可行的选择时,就会发生这种情况。在这种情况下,<strong>分支</strong>策略用于从多个选择中进行采样并选择最佳结果。<br></p>elif ent 5.0: temp_adj = 1.2 + 0.3 * interaction_strength top_k_adj = max(5, int(top_k * (1 + 0.5 * (1 - agreement)))) return _sample(logits, temperature=min(1.5, temperature * temp_adj), top_p=top_p, top_k=top_k_adj, min_p=min_p, generator=generator)代码链接
虽然这个策略被称为“分支”,但当前的代码似乎是调整采样范围并选择单个路径。 (如果有人有更多见解,我们将不胜感激。)
3. 高熵、低变熵 → cot 或插入暂停令牌
当下一个标记的预测概率相当均匀时,表明下一个上下文不确定,则插入一个澄清标记来解决歧义。
elif ent > 3.0 and vent <p>代码链接</p> <h4> 4. 高熵、高变熵 → 重采样 </h4> <p>在这种情况下,存在多个上下文,并且下一个标记的预测概率较低。 <strong>重采样</strong>策略使用更高的温度设置和更低的top-p。<br></p>elif ent > 5.0 and vent > 5.0: temp_adj = 2.0 + 0.5 * attn_vent top_p_adj = max(0.5, top_p - 0.2 * attn_ent) return _sample(logits, temperature=max(2.0, temperature * temp_adj), top_p=top_p_adj, top_k=top_k, min_p=min_p, generator=generator)代码链接
中级案例
如果以上条件均不满足,则执行自适应采样。采取多个样本,根据熵、变熵和注意力信息计算最佳采样分数。
else: return adaptive_sample( logits, metrics, gen_tokens, n_samples=5, base_temp=temperature, base_top_p=top_p, base_top_k=top_k, generator=generator )代码链接
参考
- entropix 存储库
- entropix 在做什么?
以上就是Entropix:最大化推理性能的采样技术的详细内容,更多请关注其它相关文章!