Node.js 内部结构
假设你去一家餐厅,有一位厨师承诺“我可以同时为数百人做饭,而你们不会挨饿”,听起来不可能,对吧?您可以将这个单一检查视为 node js,它管理所有这些多个订单,并且仍然为所有顾客提供食物。
每当你问某人“什么是 node js?”时,人们总是得到答案“node js 是一个运行时,用于在浏览器环境之外运行 javasc++ript”。
但是,运行时是什么意思?...运行时环境是一种软件基础设施,其中代码执行被编写成特定的编程语言。它拥有运行代码、处理错误、管理内存以及与底层操作系统或硬件交互的所有工具、库和功能。
node js 拥有所有这些。
google v8 引擎来运行代码。
fs、crypto、http 等核心库和 api
libuv 和事件循环等基础设施支持异步和非阻塞 i/o 操作。
所以,我们现在可以知道为什么 node js 被称为运行时了。
此运行时由两个独立的依赖项组成,v8 和 libuv.
v8 是 google chrome 中也使用的引擎,由 google 开发和管理。在 node js 中,它执行 javascript 代码。当我们运行命令 node index.js 时,node js 会将此代码传递给 v8 引擎。 v8 处理该代码、执行它并提供结果。例如,如果您的代码记录“hello, world!”对于控制台,v8 处理实现此操作的实际执行。
libuv 库包含 c++ 代码,当我们需要网络、i/o 操作或与时间相关的操作等功能时,可以使用该代码访问操作系统。它充当 node js 和操作系统之间的桥梁。
libuv 处理以下操作:
文件系统操作:读取或写入文件(fs.readfile、fs.writefile)。
网络:处理 http 请求、套接字或连接到服务器。
计时器:管理 settimeout 或 setinterval 等函数。
文件读取等任务由 libuv 线程池处理,计时器由 libuv 的计时器系统处理,网络调用由操作系统级 api 处理。
node js 是单线程的吗?
看下面的例子。
const fs = require('fs');
const path = require('path');
const filepath = path.join(__dirname, 'file.txt');
const readfilewithtiming = (index) => {
const start = date.now();
fs.readfile(filepath, 'utf8', (err, data) => {
if (err) {
console.error(`error reading the file for task ${index}:`, err);
return;
}
const end = date.now();
console.log(`task ${index} completed in ${end - start}ms`);
});
};
const startoverall = date.now();
for (let i = 1; i <= 4; i++) {
readfilewithtiming(i);
}
process.on('exit', () => {
const endoverall = date.now();
console.log(`total execution time: ${endoverall - startoverall}ms`);
});
我们正在读取同一个文件四次,并且我们正在记录读取这些文件的时间。
我们得到此代码的以下输出。
task 1 completed in 50ms task 2 completed in 51ms task 3 completed in 52ms task 4 completed in 53ms total execution time: 54ms
我们可以看到我们几乎在第 50 毫秒完成了所有四个文件的读取。如果 node js 是单线程的话,那么这些文件读取操作是如何同时完成的呢?
这个问题回答了libuv库使用线程池。线程池是一堆线程。默认情况下,线程池大小为 4,意味着 libuv 可以一次处理 4 个请求。
考虑另一种情况,我们不是读取一个文件 4 次,而是读取该文件 6 次。
const fs = require('fs');
const path = require('path');
const filepath = path.join(__dirname, 'file.txt');
const readfilewithtiming = (index) => {
const start = date.now();
fs.readfile(filepath, 'utf8', (err, data) => {
if (err) {
console.error(`error reading the file for task ${index}:`, err);
return;
}
const end = date.now();
console.log(`task ${index} completed in ${end - start}ms`);
});
};
const startoverall = date.now();
for (let i = 1; i <= 6; i++) {
readfilewithtiming(i);
}
process.on('exit', () => {
const endoverall = date.now();
console.log(`total execution time: ${endoverall - startoverall}ms`);
});
输出将如下所示:
task 1 completed in 50ms task 2 completed in 51ms task 3 completed in 52ms task 4 completed in 53ms task 5 completed in 101ms task 6 completed in 102ms total execution time: 103ms
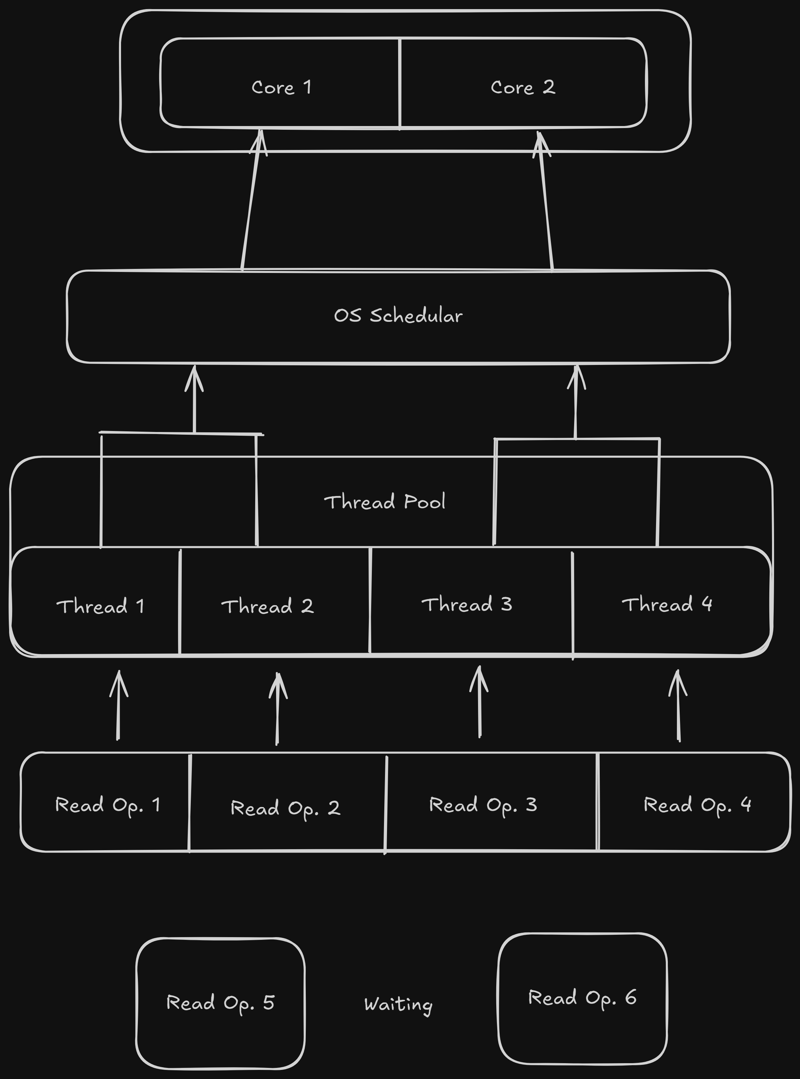
假设读操作1和2完成并且线程1和2空闲。
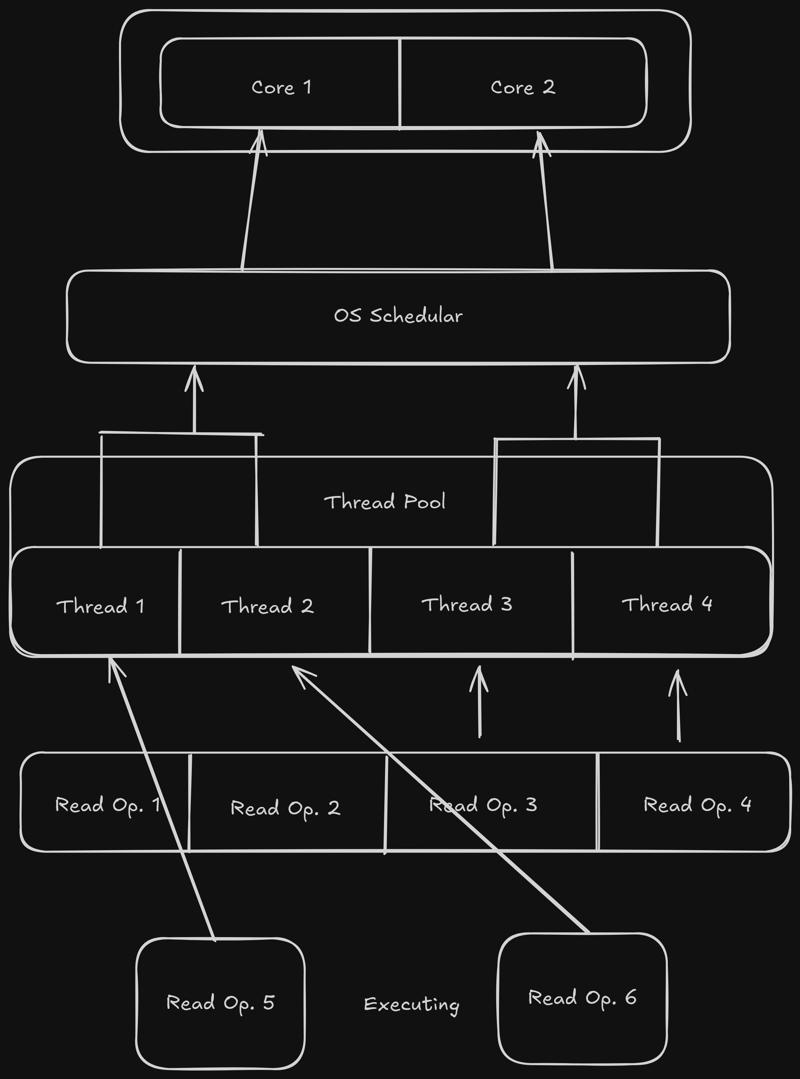
您可以看到,前 4 次我们读取文件的时间几乎相同,但是当我们第 5 次和第 6 次读取该文件时,完成读取操作所需的时间几乎是前 4 次读取操作的两倍。
发生这种情况是因为线程池大小默认为 4,因此同时处理四个读取操作,但我们再次读取文件 2 次(第 5 次和第 6 次),然后 libuv 等待,因为所有线程都有一些工作。当四个线程之一完成执行时,将对该线程处理第 5 次读操作,并且将执行第 6 次读操作。这就是为什么需要更多时间的原因。
所以,node js 不是单线程的。
但是,为什么有些人将其称为单线程?
这是因为主事件循环是单线程的。该线程负责执行 node js 代码,包括处理异步回调和协调任务。它不直接处理文件 i/o 等阻塞操作。
代码执行流程是这样的。
- 同步代码(v8):
node.js 使用 v8 javascript 引擎逐行执行所有同步(阻塞)代码。
- 委派的异步任务:
诸如 fs.readfile、settimeout 或 http 请求之类的异步操作被发送到 libuv 库或其他子系统(例如操作系统)。
- 任务执行:
文件读取等任务由 libuv 线程池处理,计时器由 libuv 的计时器系统处理,网络调用由操作系统级 api 处理。
- 回调排队:
异步任务完成后,其关联的回调将被发送到事件循环的队列。
- 事件循环执行回调:
事件循环从队列中获取回调并一一执行它们,确保非阻塞执行。
您可以使用 process.env.uv_threadpool_size = 8.
更改线程池大小现在,我在想,如果我们设置大量的线程,那么我们也将能够处理大量的请求。我希望你能像我一样思考这个问题。
但是,这与我们的想法相反。
如果我们增加线程数量超过一定限制,那么它会减慢你的代码执行速度。
看下面的例子。
const fs = require('fs');
const path = require('path');
// set uv_threadpool_size to 100 (a high value) for this example
process.env.uv_threadpool_size = 100;
const filepath = path.join(__dirname, 'largefile.txt');
// function to simulate reading multiple files asynchronously
const readfilewithtiming = (index) => {
const start = date.now();
fs.readfile(filepath, 'utf8', (err, data) => {
if (err) {
console.error(`error reading the file for task ${index}:`, err);
return;
}
const end = date.now();
console.log(`task ${index} completed in ${end - start}ms`);
});
};
const startoverall = date.now();
for (let i = 1; i <= 10; i++) {
readfilewithtiming(i);
}
process.on('exit', () => {
const endoverall = date.now();
console.log(`total execution time: ${endoverall - startoverall}ms`);
});
输出:
具有高线程池大小(100 个线程)
task 1 completed in 100ms task 2 completed in 98ms task 3 completed in 105ms task 4 completed in 95ms task 5 completed in 120ms task 6 completed in 130ms task 7 completed in 135ms task 8 completed in 140ms task 9 completed in 125ms task 10 completed in 150ms total execution time: 700ms
现在,以下输出是当我们将线程池大小设置为 4(默认大小)时的输出。
使用默认线程池大小(4 个线程)
Task 1 completed in 100ms Task 2 completed in 98ms Task 3 completed in 105ms Task 4 completed in 95ms Task 5 completed in 100ms Task 6 completed in 98ms Task 7 completed in 102ms Task 8 completed in 104ms Task 9 completed in 106ms Task 10 completed in 99ms Total execution time: 600ms
可以看到总的执行时间有100ms的差异。总执行时间(线程池大小 4)为 600 毫秒,总执行时间(线程池大小 100)为 700 毫秒。因此,线程池大小为 4 花费的时间更少。
为什么线程数多!=可以同时处理更多任务?
第一个原因是每个线程都有自己的堆栈和资源需求。如果增加线程数量,最终会导致内存或 cpu 资源不足的情况。
第二个原因是操作系统必须调度线程。如果线程太多,操作系统将花费大量时间在线程之间切换(上下文切换),这会增加开销并降低性能,而不是提高性能。
现在,我们可以说,这不是增加线程池大小以实现可扩展性和高性能,而是使用正确的架构,例如集群,并了解任务性质(i/o 与 cpu 限制) )以及 node.js 的事件驱动模型如何工作。
感谢您的阅读。
以上就是Node.js 内部结构的详细内容,更多请关注硕下网其它相关文章!