机器学习章节自然语言处理
自然语言处理 (nlp) 涉及使用机器学习模型来处理文本和语言。 nlp 的目标是教会机器理解口头和书面文字。例如,当您向 iphone 或 android 设备口述某些内容时,它会将您的语音转换为文本,这就是 nlp 算法在发挥作用。
您还可以使用 NLP 来分析文本评论并预测它是正面还是负面。 NLP 可以对文章进行分类或确定书籍的类型。它甚至可以用来创建机器翻译器或语音识别系统。在这些情况下,分类算法有助于识别语言。大多数NLP算法都是分类模型,包括逻辑回归、朴素贝叶斯、CART(决策树模型)、最大熵(也与决策树有关)和隐马尔可夫模型(基于马尔可夫过程)。
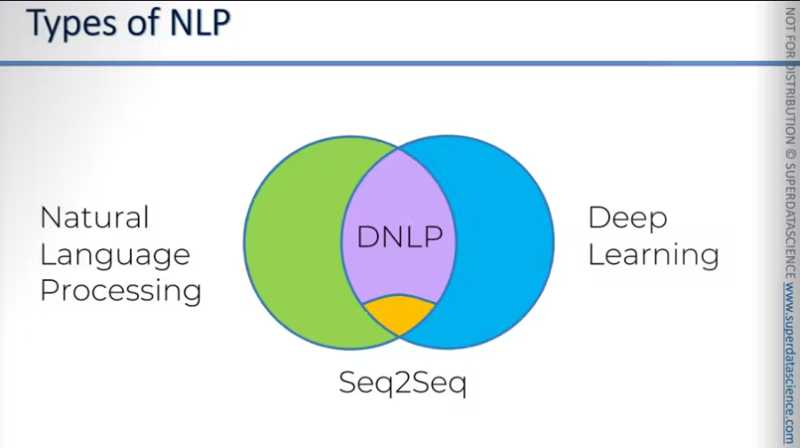
开始之前的小见解:在维恩图的左侧,我们有绿色代表 NLP。右侧,蓝色代表 DL。在十字路口,我们有 DNLP。 DNLP 有一个名为 Seq2Seq 的小节。 Sequence to Sequence是目前NLP最前沿、最强大的模型。不过,我们不会在本博客中讨论 seq2seq。我们将基本上介绍词袋分类。
在这一部分中,您将了解并学习如何:
- 清理文本,为机器学习模型做好准备。
- 创建词袋模型。
- 将机器学习模型应用于此词袋模型。 这是我们将重点关注的内容。注意:我们不会讨论 Seq2Seq、聊天机器人或深度 NLP。我使用的材料来自 NLP 和 DL,所以我们将排除 DL 部分。

阅读完整博客:ML 第 7 章:自然语言处理
以上就是机器学习章节自然语言处理的详细内容,更多请关注硕下网其它相关文章!