数学+Python=爱
我建议您在创建解决方案时,一定要在数学陈述的上下文中进行思考。因为:
- 在您编码的同时轻松节省项目边界
- 节目空间有更多回旋的机会
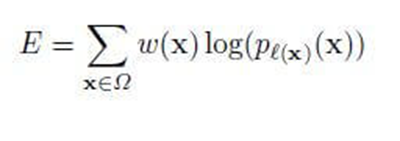
人工智能的交叉熵有助于在每个时代的最佳实践中训练神经网络。经常使用不同的数学构造,例如随机下降法。
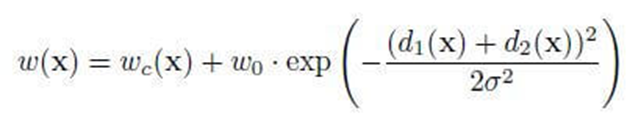
权重系数图以正确的方式集中我们的特征神经网络。为了避免结果值出现严重错误。
best_w = keras.callbacks.ModelCheckpoint('unet_best.h5',
monitor='val_loss',
verbose=0,
save_best_only=True,
save_weights_only=True,
mode='auto',
period=1)
last_w = keras.callbacks.ModelCheckpoint('unet_last.h5',
monitor='val_loss',
verbose=0,
save_best_only=False,
save_weights_only=True,
mode='auto',
period=1)
callbacks = [best_w, last_w]
最好已经创建 2 个列表:模型的最佳权重和最后权重。这在计算误差值时很有用。
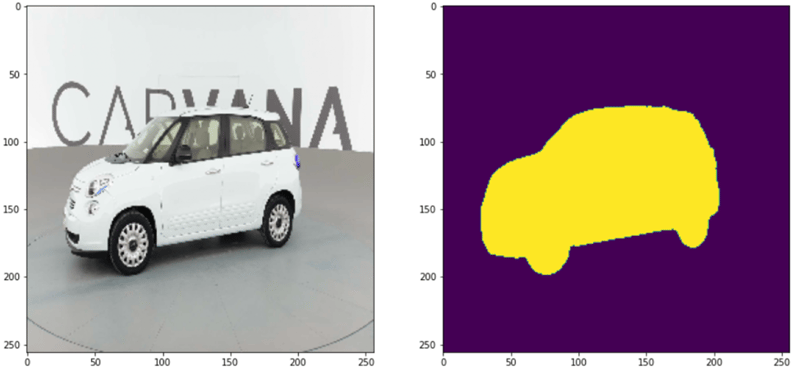
最终结果如下:
以上就是数学+Python=爱的详细内容,更多请关注硕下网其它相关文章!