MySQL学习之聊聊查询语句执行流程
如果想深入地学习 MySQL ,那么应该从宏观的架构上面着手,这一篇我们学习 MySQL 查询语句执行的流程,希望对大家有所帮助!

本篇文章 MySQL 版本为 8.0.18
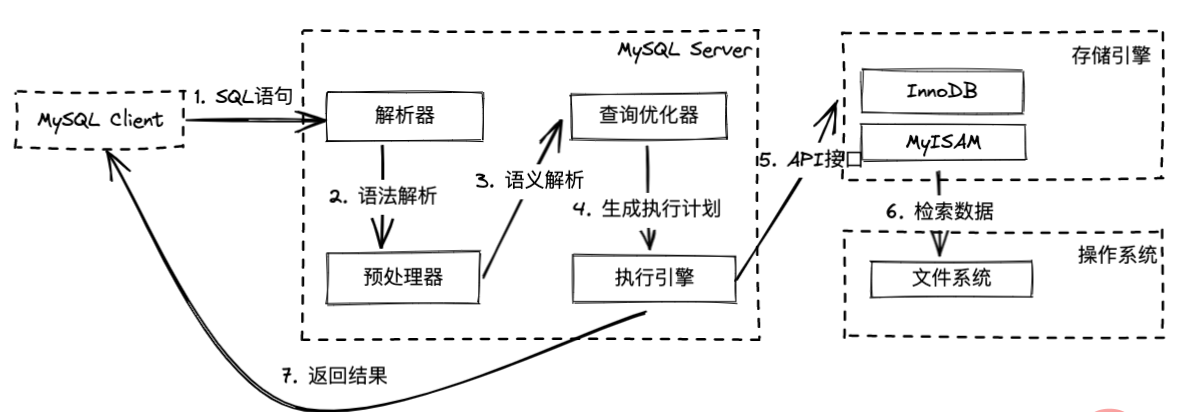
架构图
解析器
解析器的作用是对客户端传来的 SQL 语句进行以下工作:
- 语法解析:检查 SQL 语句的语法,括号、引号是否闭合等
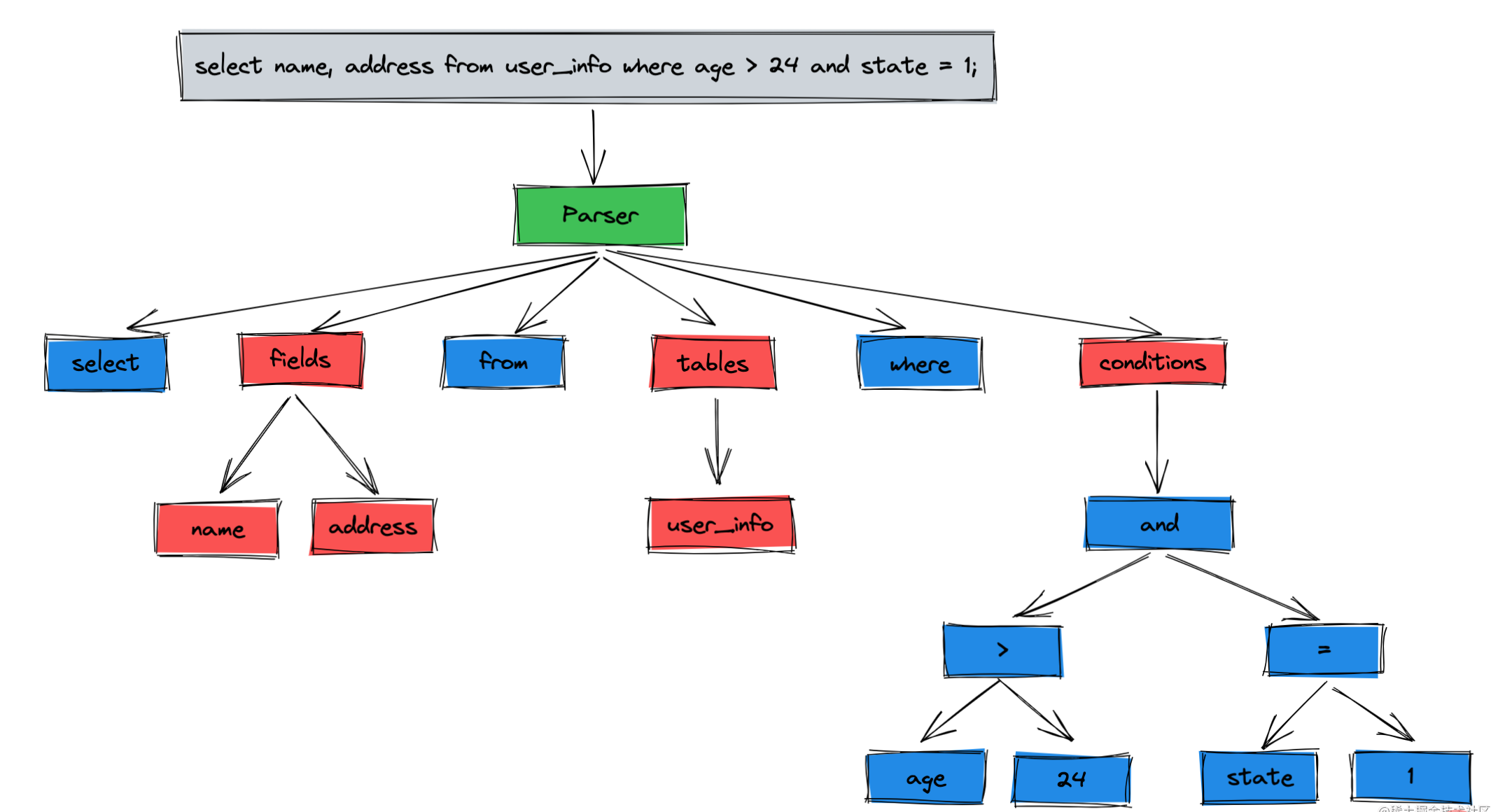
- 词法解析:把 SQL 语句中的关键词、表名、字段名拆分成一个个节点,最终得到一颗解析树
预处理器
解析器主要是检查语法词法方面,但是如果语法词法都正确,但是表、字段是不存在的,那么这段 SQL 语句也是无法正确执行的。
所以预处理器的作用是:语义解析,判断解析树的语义是否正确,表、字段这些是否存在,预处理后会得到一颗新的解析树。
查询优化器
查询优化器结构
在 MySQL 中一条 SQL 语句的执行方式有多种,虽然最终都会得到相同的结果,但是存在开销上的差异,具体选择哪一种执行方式是由查询优化器来决定的。比如说:
- 表中有多个索引可以选择,具体选择哪一个索引
- 当我们对多张表进行关联查询时,以哪一张表的数据为基准表
查询优化器是基于开销(cost)的优化器,它的工作原理是根据解析树生成的多种执行计划,会评估各种执行方式所需的开销(cost),最终会得到一个开销最小的执行计划作为最终方案。
但是这个开销最小的执行方式不一定是最优的执行方式,比如本该使用索引,却进行了全表扫描等。虽然查询优化器中有《优化》两个字,但是这个优化并不是万能的,很多时候更加需要考虑 SQL 语句书写得是否合理。
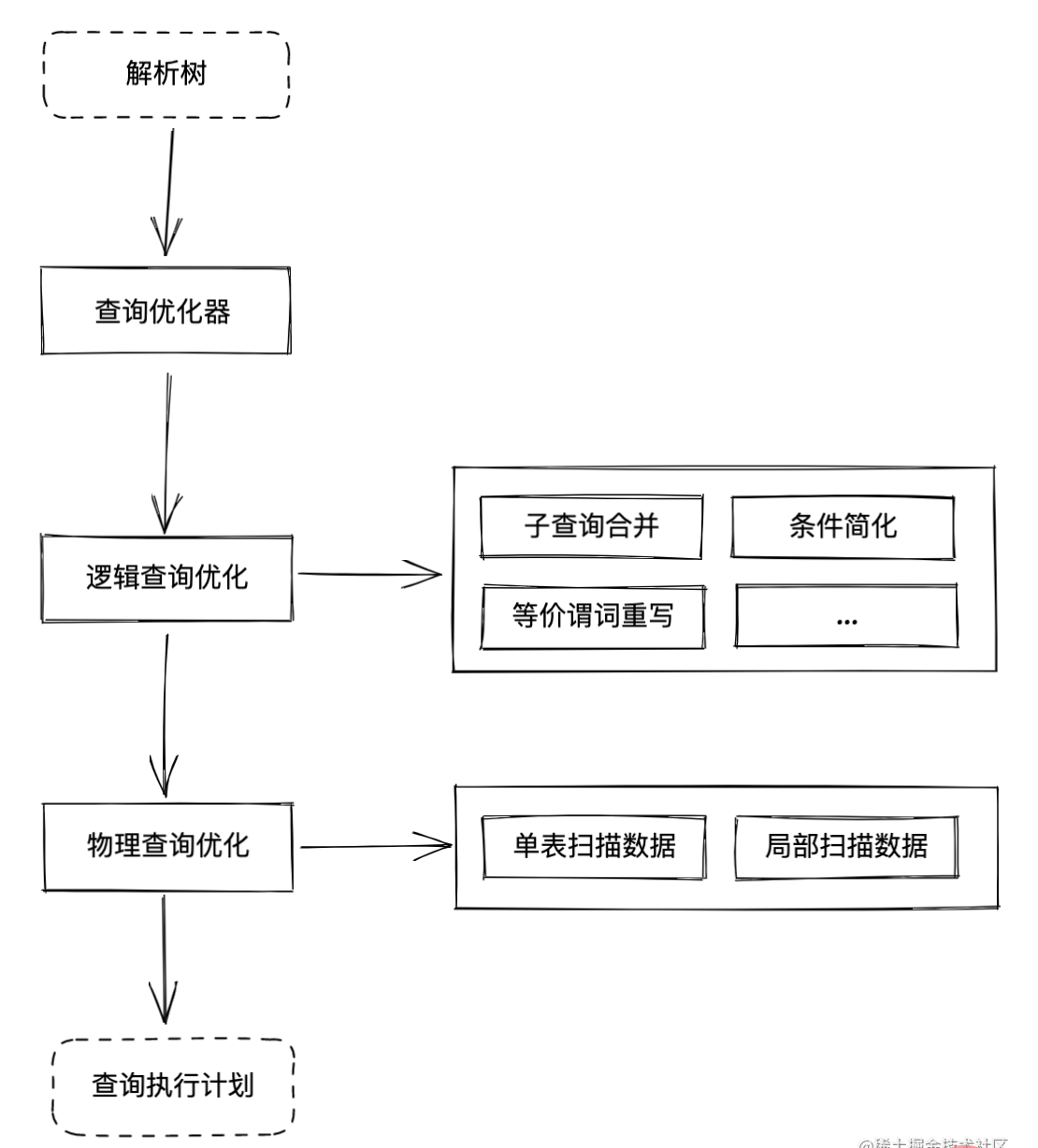
逻辑查询优化
逻辑查询优化主要负责进行一些关系代数对 SQL 语句进行优化,从而使 SQL 语句执行效率更高
逻辑查询优化我们可以使用几个案例来简单理解
子查询合并
合并前
SELECT * FROM t1 WHERE a1<10 AND ( EXISTS(SELECT a2 FROM t2 WHERE t2.a2<5 AND t2.b2=1) OR EXISTS(SELECT a2 FROM t2 WHERE t2.a2<5 AND t2.b2=2) );
合并后
SELECT * FROM t1 WHERE a1<10 AND ( EXISTS(SELECT a2 FROM t2 WHERE t2.a2<5 AND (t2.b2=1 OR t2.b2=2) );
把多个子查询通过合并查询条件而合并查询,把多次连接操作减少为单次表扫描和单次连接
等价谓词重写
像我们熟悉的 like 模糊查询,% 写在条件后面才会进行索引范围查询,其实这是查询优化器的功劳
假设使用的条件都是有建立索引的,重写前
SELECT * FROM USERINFO WHERE name LIKE 'Abc%';
重写后
SELECT * FROM USERINFO WHERE name >= 'Abc' AND name < 'Abd';
这就是为什么能进行索引范围查询的答案
条件简化
条件简化也是利用一些等式、代数关系来实现简化
- 去除表达式中的冗余括号,减少语法分析时产生的AND和OR 树的层 次,比如
((a AND b) AND (c AND d))简化为a AND b AND c AND d - 常量传递,比如
col1 = col2 AND col2 = 3简化为col1 = 3 AND col2 = 3 - 表达式计算,对于一些可直接求解的表达式会转换为最终的计算结果,比如
col1 = 1+2简化为col1 = 3
- 去除表达式中的冗余括号,减少语法分析时产生的AND和OR 树的层 次,比如
物理查询优化
物理查询优化主要做的工作是根据 SQL 语句分别对多种执行计划进行开销的评估
物理查询优化主要解决以下几个问题:
单表扫描中采用哪种方式是开销最小的(扫描索引+回表 or 全表扫描)
存在表连接的时候使用哪种连接方式是开销最小的
简单了解一下代价评估,代价评估是基于 CPU 代价和 IO 代价两个维度的
| 扫描方式 | 代价评估公式 |
|---|---|
| 顺序扫描 | N_page * a_page_IO_time + N_tuple * a_tuple_CPU_time |
| 索引扫描 | C_index + N_page_index * a_page_IO_time |
上述参数说明如下:
- a_page_IO_time, 一个数据页加载的IO耗时
- N_page,数据页数量
- N_tuple,元组数(元组理解为一行数据)
- a_tuple_CPU_time,一个元组从数据页中解析的CPU耗时
- C_index,索引的IO耗时
- N_page_index,索引页数量
关于索引成本计算可以参考这篇文章:MySQL查询为什么选择使用这个索引?——基于MySQL 8.0.22索引成本计算
执行计划
执行计划是查询优化器的产物,最终会交给存储引擎进行执行。执行计划可以帮助我们得知 MySQL 会怎么执行这条 SQL 语句。
使用 explain 关键字查看 SQL 语句的执行计划,可以得到以下信息:
- id:嵌套查询中查询的执行顺序
- possible_keys:本次查询可能用到的索引
- Key:实际用到的索引
- rows:得到结果大概要检索多少行数据
- select_type多表之间的连接类型
- extra:额外的信息,是否有索引覆盖、索引下推等
存储引擎
MySQL 服务端规定了数据如何存储、如何提取、如何更新的规范,这个规范由存储引擎来实现,不同的存储引擎的实现方式不同,所以不同的存储引擎会呈现其独特的功能和特点。其中最常用的存储引擎是 InnoDB 和 MyISAM
简单说说这两款存储引擎的特点
InnoDB:
- 支持外键、事务,保证了数据的完整性和一致性
- 支持更细的锁粒度,对锁的控制更好,读写效率更高
MyISAM
- 不支持事务,只支持行锁,适合数据只读的场景
存储引擎方面暂时先不展开,会在其他文章继续穿插他们的对比,以及会详细分析 InnoDB 更新数据的流程
总结
从前,只知道在客户端软件上写下 SQL 语句,点击执行,拿到数据
到现在终于了解到一条查询语句传入 MySQL 服务端后需要经历这一系列的操作
解析器根据这条 SQL 语句的语法、词法进行检查,如果没有错误的话会按关键词拆分成一个个节点,最终形成一棵解析树
预处理器会检查 SQL 语句的语义,检查 SQL 语句是否有歧义、字段等是否存在,形成一棵新的解析树
查询优化器拿到这个解析树生成的各种执行计划,经过逻辑查询优化、物理查询优化后得到一个开销最小的执行计划
执行引擎拿到这份执行计划调用存储引擎的接口
存储引擎根据执行计划进行数据查询,查询会查询调用操作系统中文件系统的一些接口,完成数据查询,最后返回给客户端
【相关推荐:mysql视频教程】
以上就是MySQL学习之聊聊查询语句执行流程的详细内容,更多请关注其它相关文章!