【经验总结 】Node怎么排查内存泄漏?思路分享
Node怎么排查内存泄漏?下面本篇文章就来给大家整理总结一下Node内存泄漏排查经验,希望对大家有所帮助!

在 Nodejs 服务端开发的场景中,内存泄漏 绝对是最令人头疼的问题;
但是只要项目一直在开发迭代,那么出现 内存泄漏 的问题绝对不可避免,只是出现的时间早晚而已。所以系统性掌握有效的 内存泄漏 排查方法是一名Nodejs 工程师最基础、最核心的能力。
内存泄漏处理的难点就是如何能在无数的功能、函数中找到具体是哪一个功能中的哪一个函数的第多少行到多少行引起了内存泄漏。
很遗憾目前市面上没有能够轻松定位内存泄漏的工具,所以很多初次遇到这种问题的工程师会感到茫然,一下子不知道该如何处理。
这里我以22年的一次排查 内存泄漏 的案例分享一下我的处理思路。
问题描述
2022 Q4 某天,研发用户群中反馈我们的研发平台不能访问,后台中出现了大量的异常任务未完成。
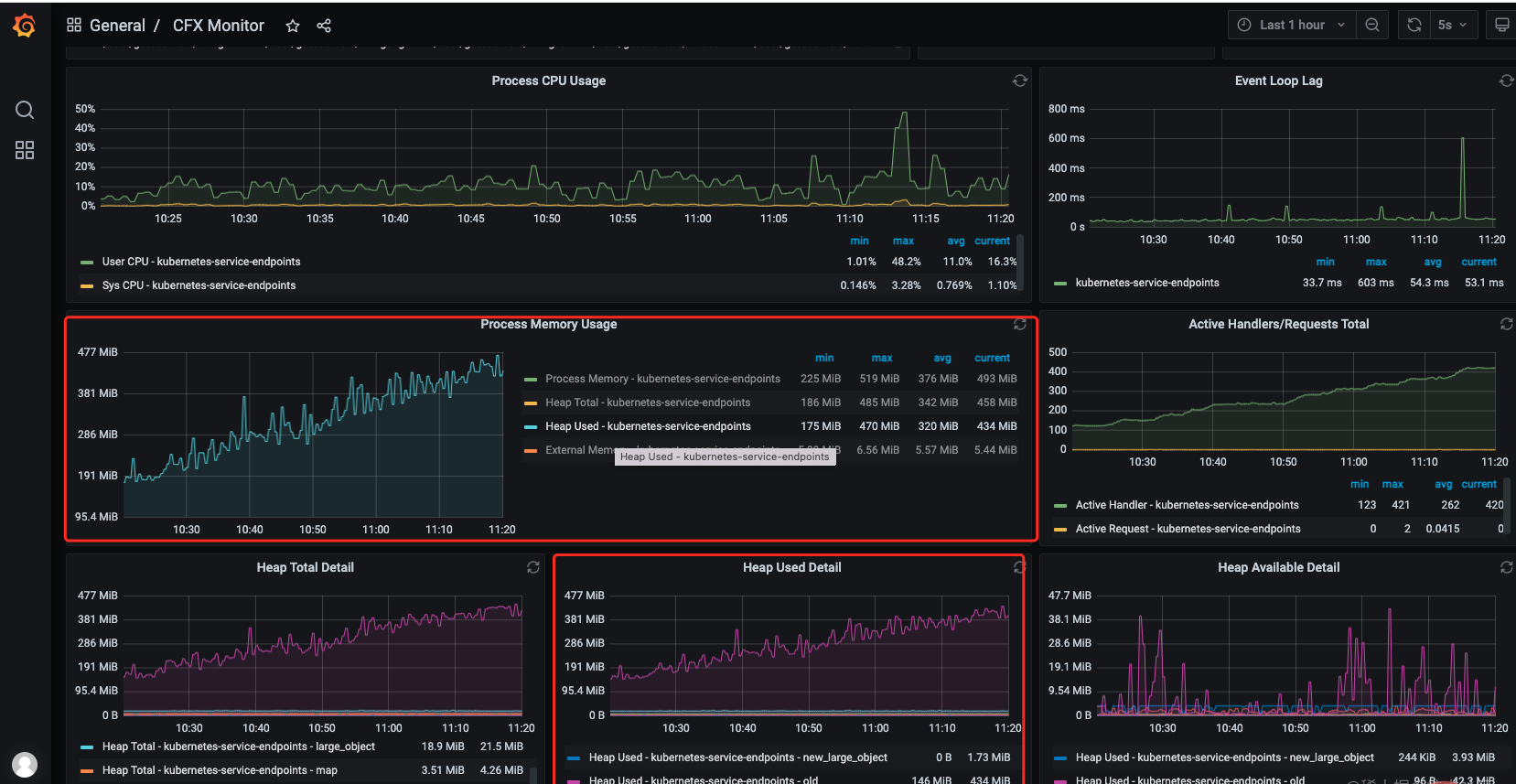
第一反应就是可能出现了内存泄漏还好服务接入了监控(prometheus + grafana),在grafana 监控面板中发现在 10.00 后内存一直在涨没有下来过出现了明显的数据泄漏。【相关教程推荐:nodejs视频教程】
说明:
process memory:rss(Resident Set Size),进程的常驻内存大小。heapTotal: V8 堆的总大小。heapUsed: V8 堆已使用的大小。external: V8 堆外的内存使用量。在
Nodejs中可以调用全局方法process.memoryUsage()获取这些数据其中heapTotal和heapUsed是 V8 堆的使用情况,V8 堆是Node.js中 JavaScript 对象存储的地方。而external则表示非 V8 堆中分配的内存,例如 C++ 对象。rss则是进程所有内存的使用量。一般看监控数据的时候重点关注heapUsed的指标就行了
内存泄漏类型
内存泄漏主要分为:
- 全局性泄漏
- 局部性泄漏
其实不管是全局性内存泄漏还是局部性的内存泄漏,要做的都是尽可能缩小排除范围。
全局性内存泄漏
全局性内容泄漏出现一般高发于:中间件与组件中,这种类型的内存泄漏排查起来也是最简单的。
很遗憾我在 2022 Q4 中遇到的内存泄漏不属于这个类型,所以还得按照局部性泄漏的思路进行分析。
二分法排查
这种类型我就不讲其它科学的分析方法了,这种情况下我认为使用二分法排查是最快的。
流程流程:
先注释一半的代码(减少一半
中间件、组件、或其它公用逻辑的使用)随便选择一个接口或新写一个测试接口进行压测
如果出现内存泄漏,那么泄漏点就在当前使用的代码之中,若没有泄漏则泄漏点出现在
然后一直循环往复上述流程大约 20 ~ 60 min 一定可以定位到内存泄漏的详细位置
2020 年的时候我在做基于
NuxtSSR 应用时,上线前压测发现应用内存泄漏,判断定为全局性的泄漏之后,采用二分法排查大约花了 30min 就成功定位了问题。
当时泄漏的原因是我们在服务端使用axios导致的泄漏,后来统一axios相关的全换成node-fetch后就解决了,从此换上了axios PDST后来绝对不会在Node服务中使用axios了
局部性内存泄漏排查
大多数内存泄漏的情况都是局部性的泄漏,泄漏点可能存在与某个中间件、某个接口、某个异步任务中,由于这样的特性它的排查难度也较大。这种情况都会做 heapdump 进行分析。
这里主要讲我这个案例中的思路关于heapdump的详细说明我放在下个段落,
Heap Dump:堆转储, 后面部分都使用heapdump表示,做heapdump的工具和教程也非常多比如:chrome、vscode、heapdump 这个开源库。我用的 heapdump 库做的网上教程非常多这里不展开了。
局部性内存泄漏排查需要一定的内存泄漏排查经验,每次遇到都把它当成对自己的一次磨砺,这样的经验积累多了以后排查内存泄漏问题会越来越快。
1. 确定内存泄漏出现的时间范围
这一点非常重要,明确了这一点可以大幅度缩小排查范围。
经常会出现这种情况,这个迭代做了A、B、C 三个功能,压测时或上线后出现了内存泄漏。那么就可以直接锁定,内存泄漏发生小这三个新的功能之中。这种情况下就不需要非常麻烦的去生产做 heapdump 我们在本地通过一些工具就可以很轻松的分析定位出内存泄漏点。
由于我们 20年Q4 的一些特殊情况,当我们发现存在内存泄漏的时候已经很难确定内存泄漏初次出现在什么时间点了,只能大概锁定在 1 月的时间内。这一个月中我们又经历了一个大版本迭代,如果一一排查这些功能与接口成本必然非常高。
所以还需要结合更多的数据进行进一步分析
2. 采集 heapdump 数据
- 生产启动时
node添加--expose-gc,这个参数会向全局注入gc()方法,方便手动触发 GC 获取更准确的堆快照数据 - 这里我加入了两个接口并带上了自己的专属权限,
- 手动触发 GC
- 打印堆快照
heapdump- 项目启动后第一次打印快照数据
- 内存上涨 100M 后:先触发 GC,再第二次打印堆快照数据
- 内存接近临界时再次触发 GC 然后打印堆快照
采集堆快照数据时需要特别注意的一些点!
- 在
heapdump时 Node 服务会中断,根据当时服务器内存大小这个时间会在 2 ~ 30min 左右。在生产环境做heapdump需要和运维一起制定合理的策略。我在这里是使用了主、备两个pod, 当主pod停掉之后,业务请求会通过负载均衡到备用pod由此保障生产业务的正常进行。(这个过程必定是一个与运维密切配合的过程,毕竟heapdump玩抽还需要通过他们拿到服务器中堆快照文件)- 上述接近临界点打印快照只是一个模糊的描述,如果你试过就知道等非常接近临界点再打印内存快照就打印不出来了。所以接近这个度需要自己把握。
- 做至少 3 次
heapdump(实际上为了拿到最详细的数据我是做了 5 次)
3. 结合监控面板的数据进行分析
需要你的应用服务接入监控,我这里应用是使用prometheus + grafana 做的监控, 主要监控服务的以下指标
QPS(每秒请求访问量) ,请求状态,及其访问路径ART(平均接口响应时间) 及其访问数据NodeJs版本Actice Handlers(句柄)Event Loop Lag(事件滞后)- 服务进程重启次数
- CPU 使用率
- 内存使用:
rss、heapTotal、heapUsed、external、heapAvailableDetail
只有
heapdump数据是不够的,heapdump数据非常晦涩,就算在可视化工具的加持下也难以准确定位问题。这个时候我是结合了grafana的一些数据一起看。
我的分析处理结果
由于当时的对快照数据丢失了,我这里模拟一下当时的场景。
1、通过 grafana 监控面看看到内存一直在涨一直下不来,但同时我也注意到,服务中的句柄数也在疯涨一直不掉。
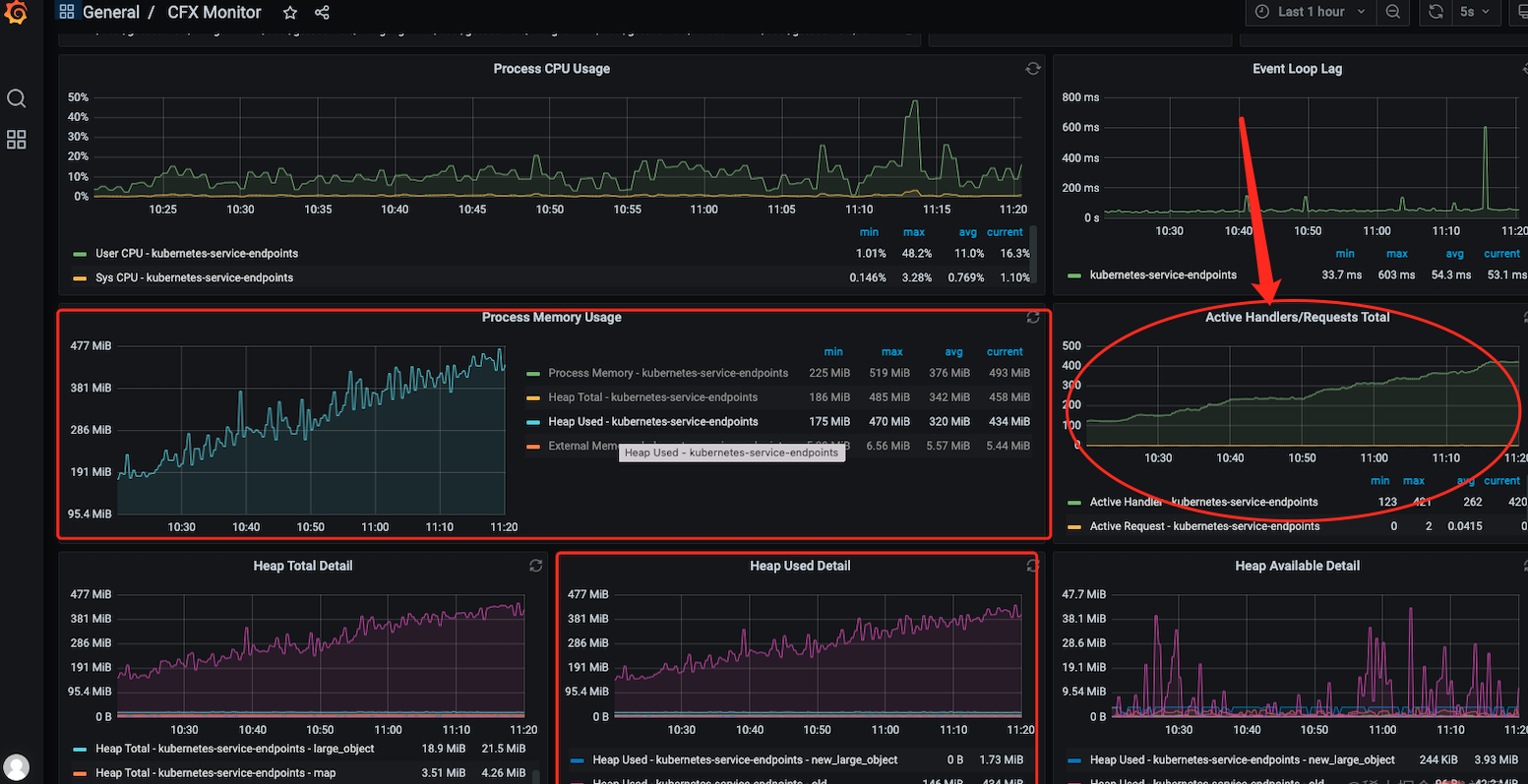
2、这是我回顾了一下出现泄漏的那一个月中新增的功能怀疑可能是在使用 bull 消息队列组件造成的内存泄漏。先去分析了相关应用代码,但并看不出那里写的有问题导致了内存泄漏,
结合 1 中句柄泄漏的问题感觉是在使用 bull 后需要手动的去释放某些资源,在这个时候还不太确定具体原因。
3、然后对 5 次的 heapdunmp 数据进行了分析,数据导入 chrome 对 5 次堆快照进行对比后,发现每次创建队列后 TCP、Socket、EventEmitter 的事件都没有被释放到。到这里基本可以确定是由于对 bull 的使用不规范导致的。在 bull 通常不会频繁创建队列,队列占用的系统资源并不会被自动释放,若有需要,需手动释放。
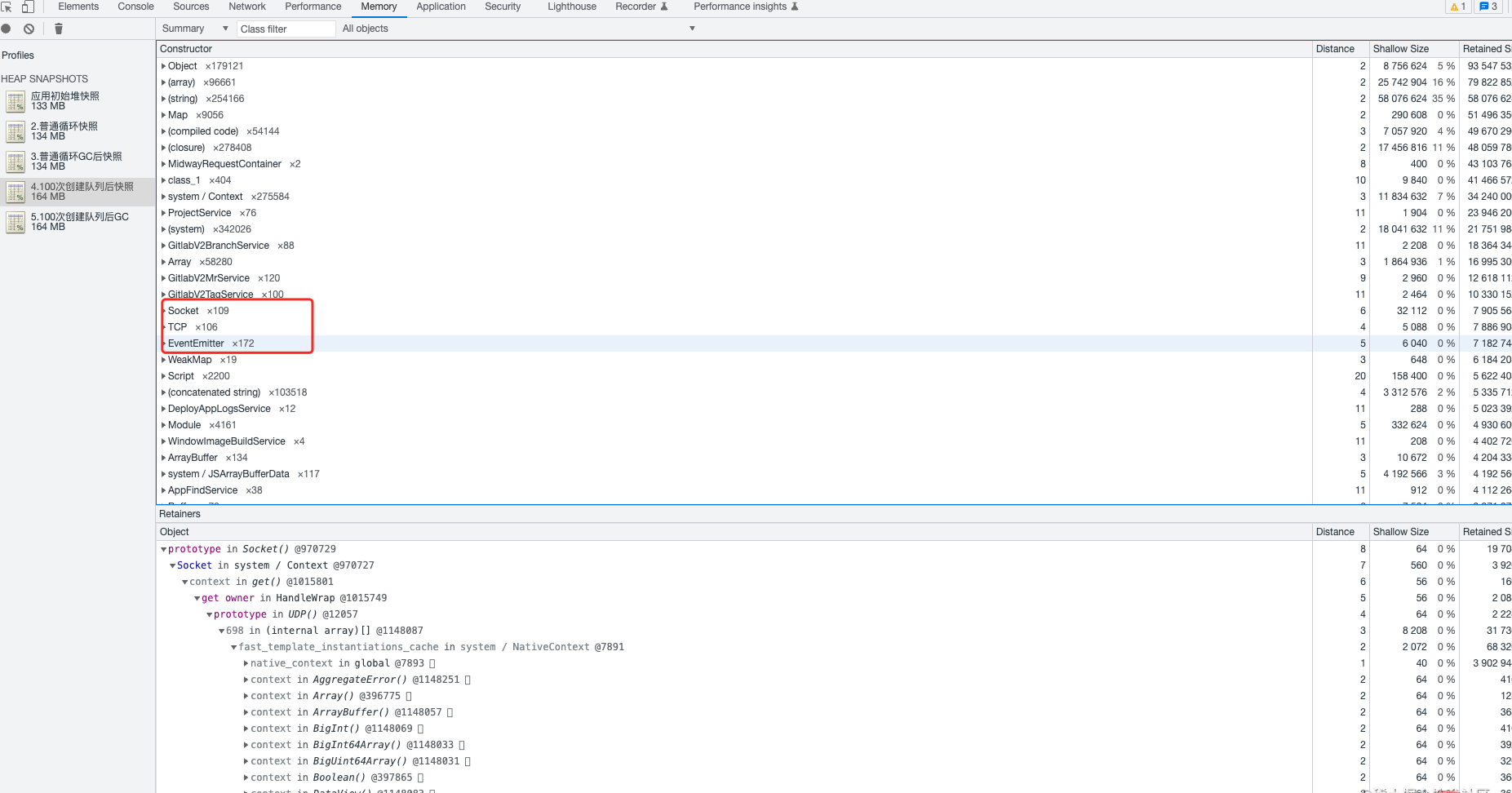
4、在调整完代码后重新进行了压测,问题解决。
Tips: Nodejs 中的
句柄是一种指针,指向底层系统资源(如文件、网络连接等)。句柄允许 Node.js 程序访问和操作这些资源,而无需直接与底层系统交互。句柄可以是整数或对象,具体取决于 Node.js 库或模块使用的句柄类型。常见句柄:
fs.open()返回的文件句柄net.createServer()返回的网络服务器句柄dgram.createSocket()返回的 UDP socket 句柄child_process.spawn()返回的子进程句柄crypto.createHash()返回的哈希句柄zlib.createGzip()返回的压缩句柄
heapdump 分析总结
通常很多人第一次拿到堆快照数据是懵的,我也是。在看了网上无数的分析技巧结合自身实战后总结了一些比较好用的技巧,一些基础的使用教程这里就不讲了。这里主要讲数据导入 chrome 后如何看图;
Summary 视图
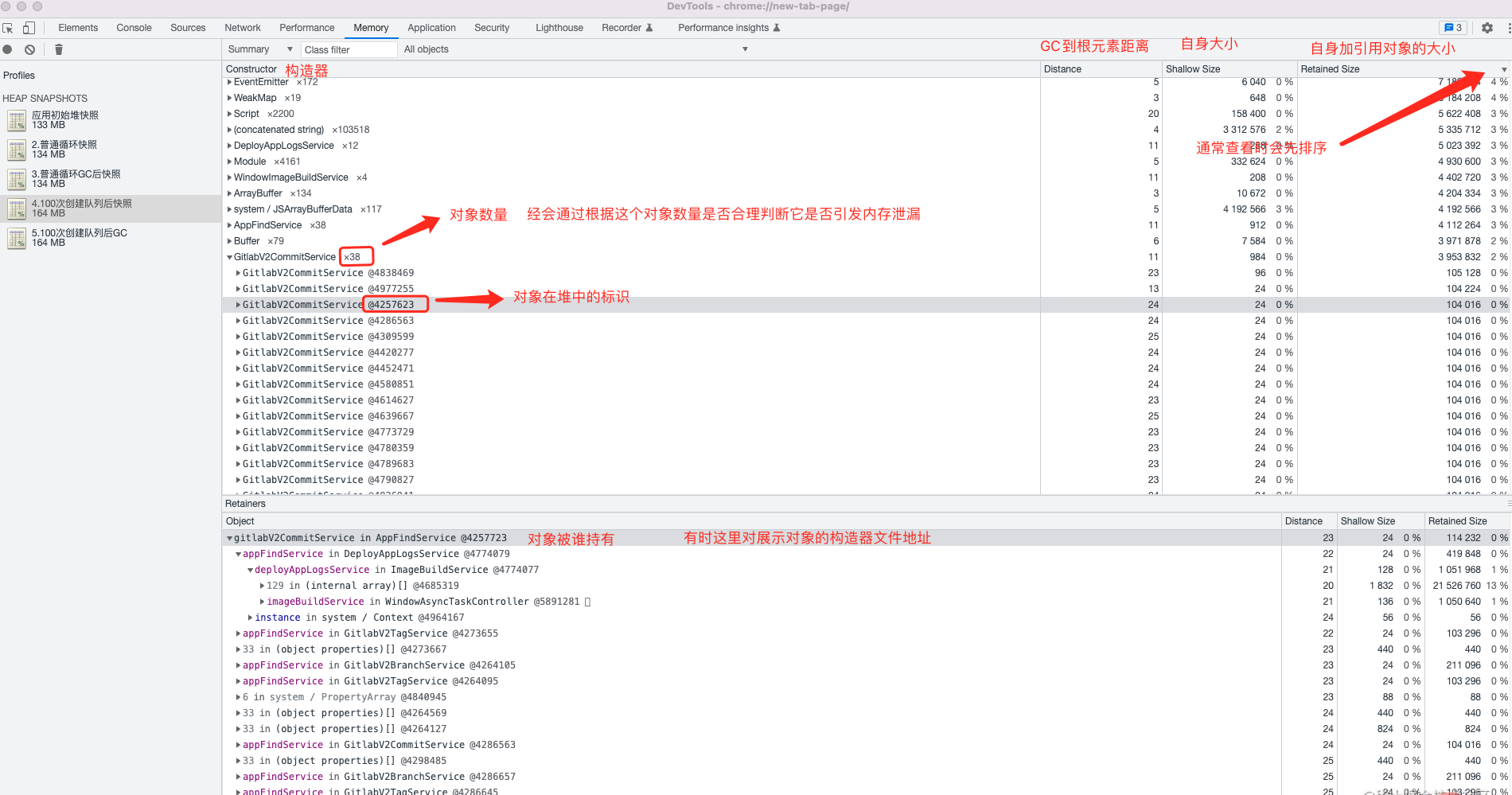 看这个视图的时候一般会先对 Retained Size 进行排查,然后观察其中对象的大小与数量,有经验的工程师,可以快速判断出某些对象数量异常。在这个视图中除了关心自己定义的一些对象之外,
一些容易发生内存泄漏的对象也需要注意如:
看这个视图的时候一般会先对 Retained Size 进行排查,然后观察其中对象的大小与数量,有经验的工程师,可以快速判断出某些对象数量异常。在这个视图中除了关心自己定义的一些对象之外,
一些容易发生内存泄漏的对象也需要注意如:
TCPSocketEventEmitterglobal
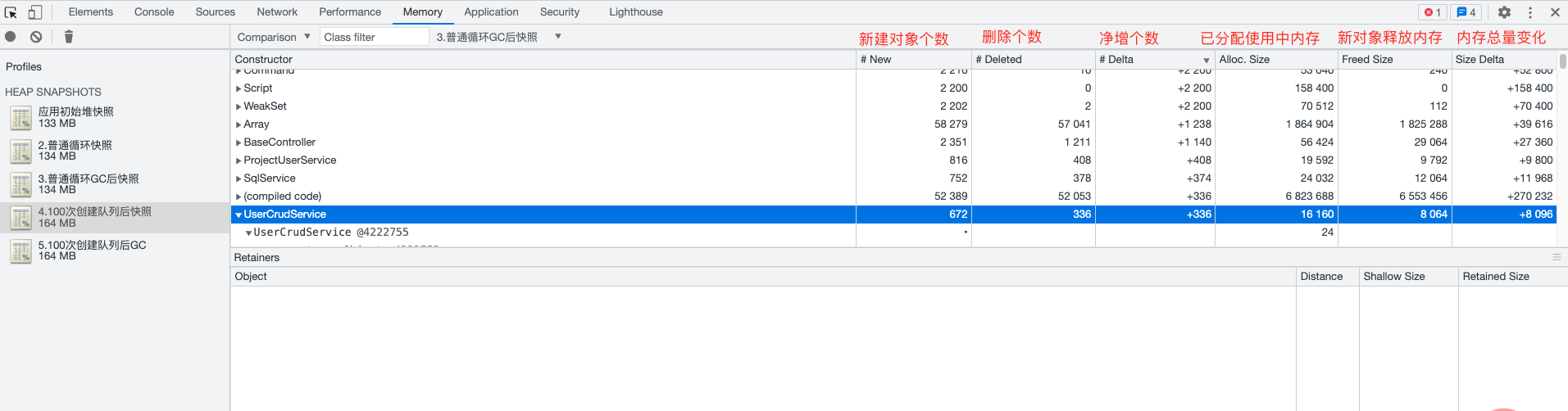
Comparison 视图
如果通过 Summary 视图, 不能定位到问题这时我们一般会使用 Comparison 视图。通过这个视图我们能对比两个堆快照中对象个数、与对象占有内存的变化;
通过这些信息我们可以判断在一段时间(某些操作)之后,堆中的对象与内存变化的数值,通过这些数值我们可以找出一些异常的对象。通过这些对象的名称属性或作用可以缩小我们内存泄漏的排查范围。
在 Comparison 视图中选择两个堆快照,并在它们之间进行比较。您可以查看哪些对象在两个堆快照之间新增,哪些对象在两个堆快照之间减少,以及哪些对象的大小发生了变化。Comparison 视图还允许查看对象之间的关系,以及对象的详细信息,如类型、大小和引用计数。通过这些信息,可以了解哪些对象是导致内存泄漏的原因。
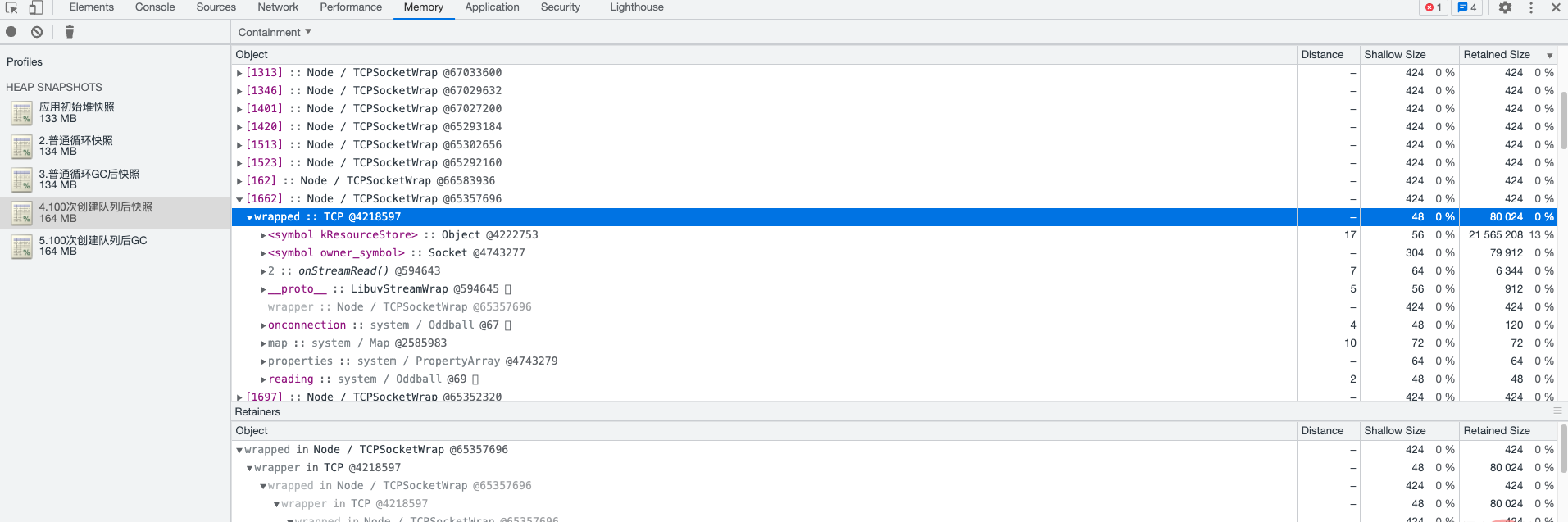
Containment 视图
显示了对象之间的所有可达的引用关系。每个对象都被表示为一个圆点,并由一条线条连接到它的父对象。通过这种方式可以查看对象之间的层次关系,并了解哪些对象是导致内存泄漏的原因。
Statistics 视图
这个图很简单不展开讲了
内存泄漏场景
- 全局变量:全局变量不会被回收
- 缓存:使用了内存密集型的第三方库如
lru-cache存的太多就会导致内存不够用,在 Nodejs 服务中建议使用redis替代lru-cache - 句柄泄漏:调用完系统资源没有释放
- 事件监听
- 闭包
- 循环引用
总结
服务需要接入监控,方便第一时间确定问题类型
判断内存泄漏是全局性的还是局部性的
全局性内存泄漏使用二分法快速排查定位
局部内存泄漏
- 确定内存泄漏出现时间点,快速定位问题功能
- 采堆快照数据,至少 3 次
- 结合监控数据、堆快照数据、与出现泄漏事时间点内的新功能对内存泄漏点进行定位
遇到内存泄漏的问题不要畏惧,多积累内存泄漏问题的排查经验处理经验多了找起来就非常快了。每次解决之后做复盘总结回头再多看看
堆快照数据利于更快的积累相关经验
其它
- 压测工具:wrk
更多node相关知识,请访问:nodejs 教程!
以上就是【经验总结 】Node怎么排查内存泄漏?思路分享的详细内容,更多请关注其它相关文章!