一起来分析Python怎么操作XML文件
本篇文章给大家带来了关于python的相关知识,其中主要介绍了Python怎么操作XML文件的相关问题,包括了XML基础概述,Python解析XML文件、写入XML文件、更新XML文件等内容,下面一起来看一下,希望对大家有帮助。

推荐学习:python视频教程
一、XML基础概述
1、XML是什么?
XML(Extensible Markup Language):即可扩展标记语言,xml是互联网数据传输的重要工具,它可以跨越互联网任何的平台,不受编程语言和的限制,可以说它是一个拥 有互联网最高级别通行证的数据携带者。xml是当前处理结构化文档信息中相当给力的技术,xml有 助于在服务器之间穿梭结构化数据,这使得开发人员更加得心应手的控制数据的存储和传输。
Xml用于标记电子文件使其具有结构性的标记语言,可以用来标记数据、定义数据类型,是-种允许用户对自己的标记语言进行定义的源语 言。Xml是标准通用标记语言(SGML) 的子集,非常适合Web传输。XML提供统-的方法来描述和交换独立于应用程序或供应商的结构化数据。
2、XML的特点及作用
特点:
- xm|与编程语言的开发平台都无关
- 实现不同系统之间的数据交互。
作用:
配置应用程序和网站;
数据交互;
Ajax基石。
3、XML文件格式
- 声明
- 根元素
- 子元素
- 属性
- 命名空间
- 限定名
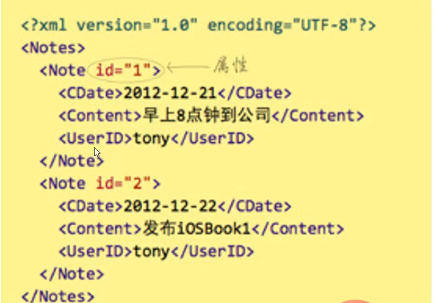
与HTML类似,XML是另一种将数据存储在标记之间的标记语言。它是人类可读和可扩展的;也就是说,我们可以自由地定义自己的标记。XML中的属性、元素和标记与HTML中的类似。XML文件可以有声明,也可以没有声明。但是,如果它有一个声明,那么它必须是XML文件的第一行。如:
<?xml version="1.0” encoding=' "UTF-8" standalone=" no”?>
这个声明语句有三部分:版本、编码和独立性。版本说明正在使用的XML标准的版本; Encoding 表示在此文件中使用的字符编码类型; Standalone 告诉解析器是否要外部信息来解释XML文件的内容。
XML文件可以表示为称为: XML 树。这个XML树从根元素(父元素)开始。这个根元素进一步分支到子元素。 XML文件的每个元素都是XML树中的一个节点。那些没有子节点的元素是叶节点。下图清楚地区分了原始XML文件和XML文件的树表示:

二、Python解析XML文件
新建一个1.xml文件:
<collection shelf="New Arrivals"> <class className="1班"> <code>2022001</code> <number>10</number> <teacher>小白</teacher> </class> <class className="2班"> <code>2022002</code> <number>20</number> <teacher>小红</teacher> </class> <class className="3班"> <code>2022003</code> <number>30</number> <teacher>小黑</teacher> </class></collection>
1、ElementTree 方式
ElementTree模块提供了一个轻量级、Pythonic的API,同时还有一个高效的C语言实现,即xml.etree.cElementTree。与DOM相比,ET的速度更快,API使用更直接、方便。与SAX相比,ET.iterparse函数同样提供了按需解析的功能,不会一次性在内存中读入整个文档。ET的性能与SAX模块大致相仿,但是它的API更加高层次,用户使用起来更加便捷。
Element对象方法:
| 类方法 | 说明 |
|---|---|
Element.iter(tag=None) | 遍历该Element所有后代,也可以指定tag进行遍历寻找。 |
Element.iterfind(path, namespaces=None) | 根据tag或path查找所有的后代。 |
Element.itertext() | 遍历所有后代并返回text值。 |
Element.findall(path) | 查找当前元素下tag或path能够匹配的直系节点 |
Element.findtext(path, default=None, namespaces=None) | 寻找第一个匹配子元素,返回其text值。匹配对象可以为tag或path。 |
Element.find(path) | 查找当前元素下tag或path能够匹配的首个直系节点。 |
Element.text | 获取当前元素的text值。 |
Element.get(key, default=None) | 获取元素指定key对应的属性值,如果没有该属性,则返回default值。 |
Element.keys() | 返回元素属性名称列表 |
Element.items() | 返回(name,value)列表 |
Element.getchildren() | |
Element.getiterator(tag=None) | |
Element.getiterator(self, tag=None) |
属性方法:
| 方法名 | 说明 |
|---|---|
Element.tag | 节点名(tag)(str) |
Element.attrib | 属性(attributes)(dict) |
Element.text | 文本(text)(str) |
Element.tail | 附加文本(tail) (str) |
Element[:] | 子节点列表(list) |
1)接下来,我们加载这个文档,并进行解析:
>>> import xml.etree.ElementTree as ET>>> tree = ET.ElementTree(file='1.xml')
2) 然后,我们获取根元素(root element):
>>> tree.getroot()<Element 'collection' at 0x000001FCC9BBFA90>
3)根元素(root)是一个Element对象。我们看看根元素都有哪些属性:
>>> root = tree.getroot()>>> root.tag, root.attrib('collection', {'shelf': 'New Arrivals'})4)根元素也具备遍历其直接子元素的接口:
>>> for child_of_root in root:... print(child_of_root.tag, child_of_root.attrib)...class {'className': '1班'}class {'className': '2班'}class {'className': '3班'}5)通过索引值来访问特定的子元素:
>>> root[0].tag, root[0].text('class', '\n\t ')
6) 查找需要的元素
从上面的示例中,可以明显发现我们能够通过简单的递归方法(对每一个元素,递归式访问其所有子元素)获取树中的所有元素。但是,由于这是十分常见的工作,ET提供了一些简便的实现方法。
Element对象有一个iter方法,可以对某个元素对象之下所有的子元素进行深度优先遍历(DFS)。ElementTree对象同样也有这个方法。下面是查找XML文档中所有元素的最简单方法:
>>> for elem in tree.iter():... print(elem.tag, elem.attrib)...collection {'shelf': 'New Arrivals'}class {'className': '1班'}code {}number {}teacher {}class {'className': '2班'}code {}number {}teacher {}class {'className': '3班'}code {}number {}teacher {}7)对树进行任意遍历——遍历所有元素,iter方法可以接受tag名称,然后遍历所有具备所提供tag的元素:
>>> for elem in tree.iter(tag='teacher'):... print(elem.tag, elem.text)...teacher 小白 teacher 小红 teacher 小黑
8)支持通过XPath查找元素
>>> for elem in tree.iterfind('class/teacher'):... print(elem.tag, elem.text)...teacher 小白 teacher 小红 teacher 小黑
9)查找所有具备某个name属性的className元素:
>>> for elem in tree.iterfind('class[@className="1班"]'):... print(elem.tag, elem.attrib)...class {'className': '1班'}10)完整解析代码
import xml.etree.ElementTree as ET
tree = ET.ElementTree(file='1.xml')print(type(tree))root = tree.getroot() # root是根元素print(type(root))print(root.tag)for index, child in enumerate(root):
print("第%s个%s元素,属性:%s" % (index, child.tag, child.attrib))
for i, child_child in enumerate(child):
print("标签:%s,内容:%s" % (child_child.tag, child_child.text))输出结果:
<class 'xml.etree.ElementTree.ElementTree'><class 'xml.etree.ElementTree.Element'>collection
第0个class元素,属性:{'className': '1班'}标签:code,内容:2022001标签:number,内容:10标签:teacher,内容:小白
第1个class元素,属性:{'className': '2班'}标签:code,内容:2022002标签:number,内容:20标签:teacher,内容:小红
第2个class元素,属性:{'className': '3班'}标签:code,内容:2022003标签:number,内容:30标签:teacher,内容:小黑2、DOM 方式
DOM (Document Object Model)将XML文档作为一棵树状结构进行分析,获取节点的内容以及相关属性,或是新增、删除和修改节点的内容。XML解析器在加载XML文件以后,DQM模式将XML文件的元素视为一个树状结构的节点,一次性读入内存。
解析代码:
from xml.dom.minidom import parse# 读取文件dom = parse('1.xml')# 获取文档元素对象elem = dom.documentElement# 获取 classclass_list_obj = elem.getElementsByTagName('class')print(class_list_obj)print(type(class_list_obj))for class_element in class_list_obj:
# 获取标签中内容
code = class_element.getElementsByTagName('code')[0].childNodes[0].nodeValue
number = class_element.getElementsByTagName('number')[0].childNodes[0].nodeValue
teacher = class_element.getElementsByTagName('teacher')[0].childNodes[0].nodeValue print('code:', code, ', number:', number, ', teacher:', teacher)输出结果:
[<DOM Element: class at 0x20141bc5c10>, <DOM Element: class at 0x20141bdf940>, <DOM Element: class at 0x20141bdfb80>]<class 'xml.dom.minicompat.NodeList'>code: 2022001 , number: 10 , teacher: 小白 code: 2022002 , number: 20 , teacher: 小红 code: 2022003 , number: 30 , teacher: 小黑
三、Python写入XML文件
doc.writexml():生成xml文档,将创建的存在于内存中的xml文档写入本地硬盘中,这时才能看到新建的xml文档
语法格式:writexml(file,indent=’’,addindent=’’,newl=’’,endocing=None)
参数说明:
file:要保存为的文件对象名indent:根节点的缩进方式allindent:子节点的缩进方式newl:针对新行,指明换行方式encoding:保存文件的编码方式
案例代码:
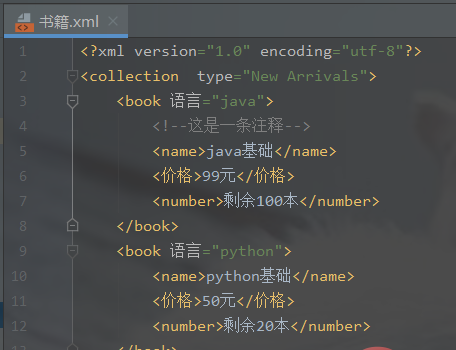
import xml.dom.minidom # 1、在内存中创建一个空的文档doc = xml.dom.minidom.Document() # 2、创建根元素root = doc.createElement('collection ')# print('添加的xml标签为:',root.tagName) # 3、设置根元素的属性root.setAttribute('type', 'New Arrivals') # 4、将根节点添加到文档对象中doc.appendChild(root) # 5、创建子元素book = doc.createElement('book') # 6、添加注释book.appendChild(doc.createComment('这是一条注释')) # 7、设置子元素的属性book.setAttribute('语言', 'java') # 8、子元素中嵌套子元素,并添加文本节点name = doc.createElement('name')name.appendChild(doc.createTextNode('java基础'))price = doc.createElement('价格')price.appendChild(doc.createTextNode('99元'))number = doc.createElement('number')number.appendChild(doc.createTextNode('剩余100本'))# 9、将子元素添加到boot节点中book.appendChild(name)book.appendChild(price)book.appendChild(number)# 10、将book节点添加到root根元素中root.appendChild(book)# 创建子元素book = doc.createElement('book')# 设置子元素的属性book.setAttribute('语言', 'python')# 子元素中嵌套子元素,并添加文本节点name = doc.createElement('name')name.appendChild(doc.createTextNode('python基础'))price = doc.createElement('价格')price.appendChild(doc.createTextNode('50元'))number = doc.createElement('number')number.appendChild(doc.createTextNode('剩余20本'))# 将子元素添加到boot节点中book.appendChild(name)book.appendChild(price)book.appendChild(number)# 将book节点添加到root根元素中root.appendChild(book)print(root.toxml())fp = open('./书籍.xml', 'w', encoding='utf-8') # 需要指定utf-8的文件编码格式,不然notepad中显示十六进制doc.writexml(fp, indent='', addindent='\t', newl='\n', encoding='utf-8')fp.close()
生成书籍.xml文件:
四、Python更新XML文件
向xml中插入新的子元素
案例代码:
import xml.dom.minidomfrom xml.dom.minidom import parse# 对book.xml新增一个子元素english,并删除math元素xml_file = './书籍.xml'# 拿到根节点domTree = parse(xml_file)rootNode = domTree.documentElement# rootNode.removeChild(rootNode.getElementsByTagName('book')[0])# print(rootNode.toxml())# 在内存中创建一个空的文档doc = xml.dom.minidom.Document()book = doc.createElement('book')book.setAttribute('语言', 'c++')# 子元素中嵌套子元素,并添加文本节点name = doc.createElement('name')name.appendChild(doc.createTextNode('c++基础'))price = doc.createElement('价格')price.appendChild(doc.createTextNode('200元'))number = doc.createElement('number')number.appendChild(doc.createTextNode('剩余300本'))# 将子元素添加到boot节点中book.appendChild(name)book.appendChild(price)book.appendChild(number)math_book = rootNode.getElementsByTagName('book')[0]# insertBefore方法 父节点.insertBefore(新节点,父节点中的子节点)rootNode.insertBefore(book, math_book)# appendChild将新产生的子元素在最后插入rootNode.appendChild(book)print(rootNode.toxml())with open(xml_file, 'w', encoding='utf-8') as fh:
domTree.writexml(fh, indent='', addindent='\t', newl='', encoding='utf-8')输出结果:添加了新节点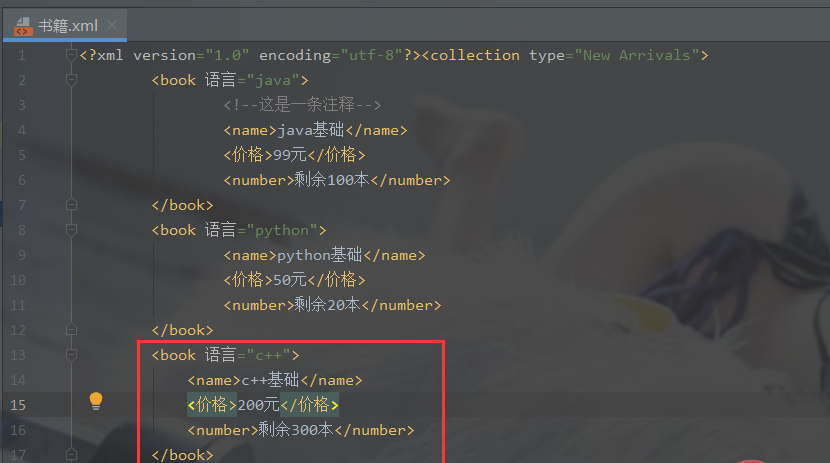
五、XML文件和JSON文件互转
记录工作中常用的一个小技巧
cmd控制台安装第三方模块:
pip install xmltodict
1、XML文件转为JSON文件
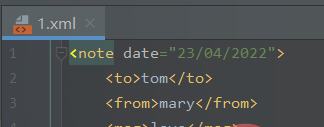
新建一个1.xml文件:
<note date="23/04/2022"> <to>tom</to> <from>mary</from> <msg>love</msg></note>
转换代码实现:
import jsonimport xmltodictdef xml_to_json(xml_str):
"""parse是的xml解析器,参数需要
:param xml_str: xml字符串
:return: json字符串
"""
xml_parse = xmltodict.parse(xml_str)
# json库dumps()是将dict转化成json格式,loads()是将json转化成dict格式。
# dumps()方法的ident=1,格式化json
json_str = json.dumps(xml_parse, indent=1)
return json_str
XML_PATH = './1.xml' # xml文件的路径with open(XML_PATH, 'r') as f:
xmlfile = f.read()
with open(XML_PATH[:-3] + 'json', 'w') as newfile:
newfile.write(xml_to_json(xmlfile))输出结果(生成json文件):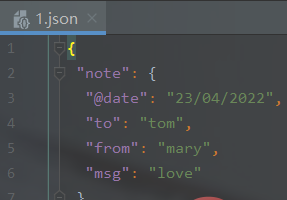
2、JSON文件转换为XML文件
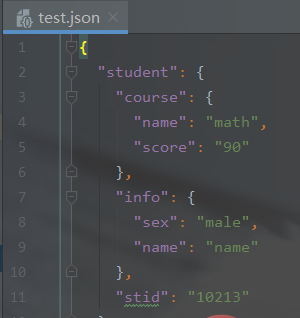
新建test.json文件:
{
"student": {
"course": {
"name": "math",
"score": "90"
},
"info": {
"sex": "male",
"name": "name"
},
"stid": "10213"
}}
转换代码实现:
import xmltodictimport jsondef json_to_xml(python_dict): """xmltodict库的unparse()json转xml :param python_dict: python的字典对象 :return: xml字符串 """ xml_str = xmltodict.unparse(python_dict) return xml_str JSON_PATH = './test.json' # json文件的路径with open(JSON_PATH, 'r') as f: jsonfile = f.read() python_dict = json.loads(jsonfile) # 将json字符串转换为python字典对象 with open(JSON_PATH[:-4] + 'xml', 'w') as newfile: newfile.write(json_to_xml(python_dict))
输出结果(生成xml文件):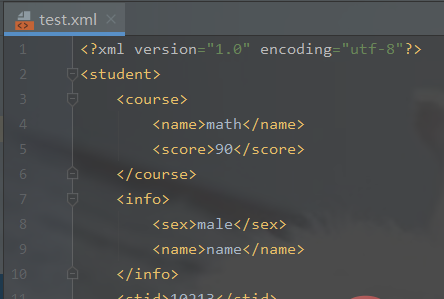
推荐学习:python视频教程
以上就是一起来分析Python怎么操作XML文件的详细内容,更多请关注其它相关文章!