一起聊聊python文件数据分析治理提取

【相关推荐:Python3视频教程 】
前提提要
python2.0有无法直接读取中文路径的问题,需要另外写函数。python3.0在2018年的时候也无法直接读取。
现在使用的时候,发现python3.0是可以直接读取中文路径的。
需要自带或者创建几个txt文件,里面最好写几个数据(姓名,手机号,住址)
要求
写代码的时候最好,自己设几个要求,明确下目的:
- 需要读取对应目录路径的所有对应文件
- 按行读取出每个对应txt文件的记录
- 使用正则表达式获取每行的手机号
- 将手机号码存储到excel中
思路
- 1)读取文件
- 2)读取数据
- 3)数据整理
- 4)正则表达式匹配
- 5)数据去重
- 6)数据导出保存
代码
import glob
import re
import xlwt
filearray=[]
data=[]
phone=[]
filelocation=glob.glob(r'课堂实训/*.txt')
print(filelocation)
for i in range(len(filelocation)):
file =open(filelocation[i])
file_data=file.readlines()
data.append(file_data)
print(data)
combine_data=sum(data,[])
print(combine_data)
for a in combine_data:
data1=re.search(r'[0-9]{11}',a)
phone.append(data1[0])
phone=list(set(phone))
print(phone)
print(len(phone))
#存到excel中
f=xlwt.Workbook('encoding=utf-8')
sheet1=f.add_sheet('sheet1',cell_overwrite_ok=True)
for i in range(len(phone)):
sheet1.write(i,0,phone[i])
f.save('phonenumber.xls')运行结果

会生成一个excel文件

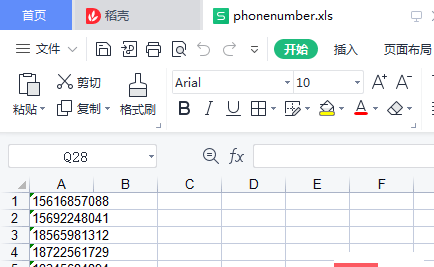
分析
import glob import re import xlwt
globe用来定位文件,re正则表达式,xlwt用于excel
1)读取文件
filelocation=glob.glob(r'课堂实训/*.txt')
指定目录下的所有txt文件
2)读取数据
for i in range(len(filelocation)): file =open(filelocation[i]) file_data=file.readlines() data.append(file_data) print(data)
将路径下的txt文件循环读取,按序号依次读取文件
打开每一次循环对应的文件
将每一次循环的txt文件的数据按行读取出来
使用append()方法将每一行的数据添加到data列表中
输出一下,可以看到将几个txt的文件数据以字列形式存在同一个列表
3)数据整理
combine_data=sum(data,[])
列表合并成一个列表
4)正则表达式匹配外加数据去重
print(combine_data)
for a in combine_data:
data1=re.search(r'[0-9]{11}',a)
phone.append(data1[0])
phone=list(set(phone))
print(phone)
print(len(phone))set()函数:无序去重,创建一个无序不重复元素集
6)数据导出保存
#存到excel中 f=xlwt.Workbook('encoding=utf-8') sheet1=f.add_sheet('sheet1',cell_overwrite_ok=True) for i in range(len(phone)): sheet1.write(i,0,phone[i]) f.save('phonenumber.xls')
- Workbook('encoding=utf-8'):设置工作簿的编码
- add_sheet('sheet1',cell_overwrite_ok=True):创建对应的工作表
- write(x,y,z):参数对应行、列、值
【相关推荐:Python3视频教程 】
以上就是一起聊聊python文件数据分析治理提取的详细内容,更多请关注其它相关文章!