Python编程:详解内置字典(dict)子类及应用(一网打尽)
前言
本主要介绍Python集合模块中几个字典类(dict)的内置扩展子类的应用场景和使用示例,还是结合代码,让你能“短平快”的来掌握这些跟dict直接关联的子类——OrderedDict、defaultdict、userDict。
OrderedDict
Python集合模块中的有序字典(OrderedDict)就像普通字典一样,但是有一些与排序操作相关的额外功能。OrderedDict会记住键插入的顺序。现在它们变得不那么重要了,因为内置的dict类获得了记住插入顺序的能力(这种新行为在Python 3.7中得到了保证,因此OrderedDict现在显得不是那么重要了)。创建有序字典的常规格式:
import collections ordDict = collections.OrderedDict([items]):
或者
from collections import OrderedDict ordDict = OrderedDict([items]):
这样就创建并返回dict子类的实例OrderedDict对象,该子类具有专门用于重新排列字典顺序的方法。本文就来简要介绍这些方法。
1)popitem(last=True):
有序字典的popitem()方法返回并删一个(key,value)对。如果last为True,则以LIFO(后进先出)方式返回相应的键值对;否则以FIFO(先进先出)顺序返回。
2)move_to_end(key, last=True):
将现有键移动到有序字典的任意一端。如果last为True(默认值),则将项移到右端;如果last为False,则移到开头。如果key不存在会引发KeyError。
请看代码:
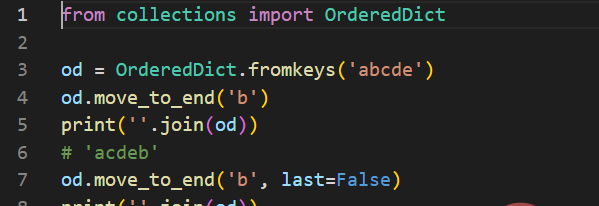
假设我们删除并重新插入相同的键到OrderedDict。它将把这个键放到末尾,以保持键的插入顺序。示例如下:
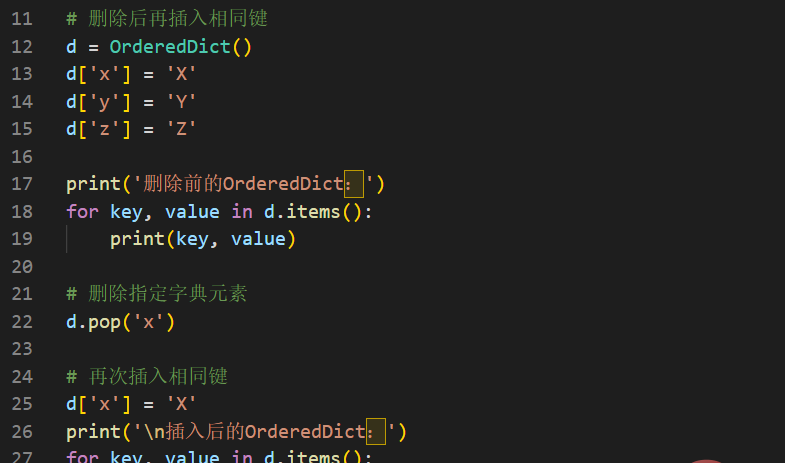
运行结果如下:
删除前的OrderedDict: x X y Y z Z 插入后的OrderedDict: y Y z Z x X
UserDict
UserDict类用作Python内置字典(dict)对象的包装器。对这个类的需求已经部分被直接从dict继承子类的能力所取代;但是,这个类更容易使用,因为底层字典可以作为属性访问。当你希望使用一些修改过的或新功能创建自己的字典时,可使用UserDict。其使用格式如下:
import collections userDict = collections.UserDict([initialdata])
或者
import collections userDict = collections.UserDict([initialdata])
此类模拟字典,其实例的内容保存在一个常规字典中,可以通过UserDict实例的data属性访问该字典。如果提供了initialdata,则用此初始化data内容;注意,实例本身不会单独保留对initialdata的引用(非独占),是允许它用于其他目的。
除了支持映射的方法和操作之外,UserDict实例提供以下属性:
1)data
一个用于存储UserDict类内容的真正字典。示例如下:
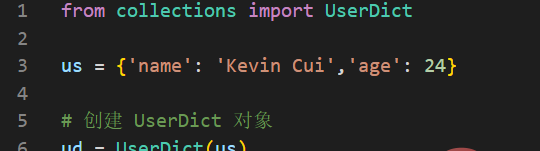
输出结果如下:
{'name': 'Kevin Cui', 'age': 24}假设我们想要定义一个支持加法操作的自定义字典对象(合并两字典)。当我们添加自定义字典的两个实例时,我们希望得到一个包含两个字典中所有元素的新字典。请记住,如果你试图添加到Python中的常规字典,则会得到TypeError。让我们在UserDict的帮助下实现它:
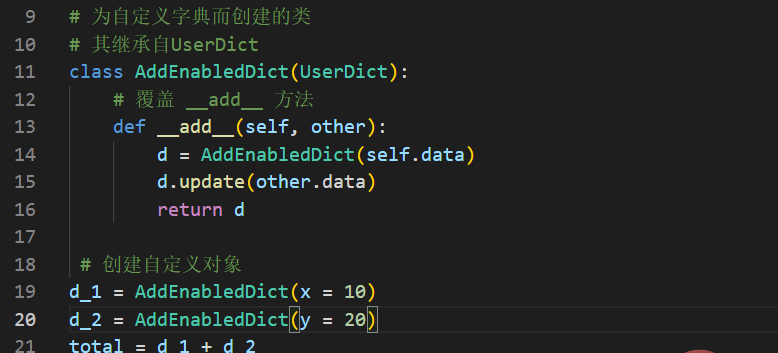
运行输出结果如下:
{'x': 10, 'y': 20}当然,你还可以自己实现其它相关的自定义操作。
DefaultDict
Python中Dictionary类的一个常见问题是缺少键。当试图访问字典中不存在的键时,将会得到一个KeyError异常。所以每当你需要访问字典中的元素时,你就必须处理这种情况。幸运的是,Python提供了DefaultDict类。它用于为不存在的键提供一些默认值且不引发KeyError。
DefaultDict是内置dict类的子类。它覆盖一个方法并添加一个可写实例变量。其余的功能与dict相同。使用格式如下:
import colloections defaultDict = collections.defaultdict(default_factory=None, /[,…])
上述代码返回一个新的类字典对象DefaultDict,它是内置dict类的子类。
第一个参数为default_factory属性提供初始值,默认为None。所有剩下的参数都被当作传递给dict构造函数一样对待,包括关键字参数。需要了解的是若提供该参数,则须是可调用的。
DefaultDict对象除了支持标准的dict操作外,还支持以下方法属性:
1)__missing__(key):
如果default_factory属性为None,用键作为参数将引发一个KeyError异常。
如果default_factory不是None,则不带参数调用它,则为给定的键提供默认值,该值被插入到键的字典中并返回。
2)default_factory
DefaultDict对象支持default_factory实例变量。该属性由__missing__()方法使用。如果存在,则从构造函数的第一个参数开始初始化;如果不存在,则初始化为None。
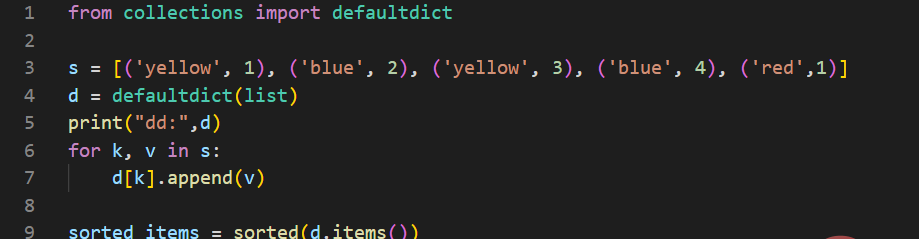
运行程序输出结果为:
[('blue', [2, 4]), ('red', [1]), ('yellow', [1, 3])]
在上述代码中,我们使用列表类型作为default_factory,更易于将包含键值序列对的列表组成字典。当第一次遇到每个键时,它还不在映射中,因此使用default_factory函数自动创建一个条目,该函数返回一个空列表。然后list.append()操作将值连接到新列表。当再次遇到键时,查找正常进行(返回该键的列表),然后list.append()操作将另一个值添加到列表中。这种技术比使用dict.setdefault()的等效技术要简单得多。
我们再看一个示例:
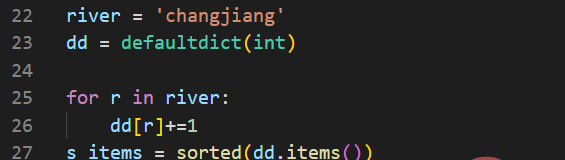
输出结果如下:
[('a', 2), ('c', 1), ('g', 2), ('h', 1), ('i', 1), ('j', 1), ('n', 2)]在上面代码中,我们将default_factory设置为int。这使得defaultdict用于计数(就像其他语言中的bag或multiset)。
当第一次遇到某个字母时,它就在映射中是不存在的,因此default_factory函数调用int()来提供一个默认的0计数。然后递增操作为每个字母建立计数。
提示:这里传递的int()函数默认返回的是整数0。若想返回任意值,可以自定义个一个基于lambda的常量函数。示例代码如下:
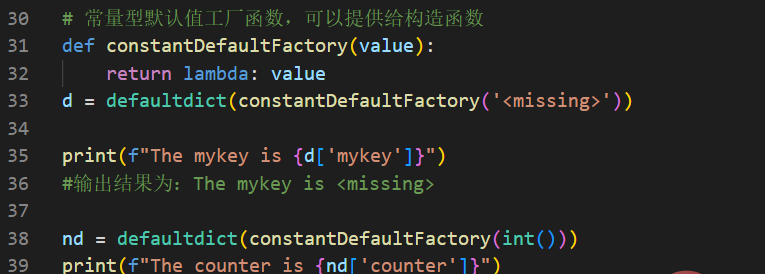
一言以蔽之:使用DefaultDict的好处就是可以避免KeyError异常,并进行一些可能的特定处理。
本文小结
本文主要介绍了Python字典(dict)类相关的几个内置子类的应用。这些直接相关的子类分别是OrderedDict、defaultdict、userDict等内置子类。通过示例代码和关联描述,让你更轻松掌握它们的应用和基本规则。
以上就是Python编程:详解内置字典(dict)子类及应用(一网打尽)的详细内容,更多请关注其它相关文章!